about me

20'S LIFE IN SYDNEY and BUSAN

EKS 스터디 CloudNet@팀의 AEWS 2기에 작성된 자료를 베이스로 작성된 블로깅입니다.저는 쿠버네티스를 접하고 사용안하고, 공부안한지 너무 오래되어서 개념을 익힐겸 핸즈온처럼 하나하나 해보았습니다.
환경설정 확인
kubectl ns default
다음 명령어로 default 네임스페이스를 사용하도록 설정을 해줍니다.
echo $EfsFsId
mount -t efs -o tls $EfsFsId:/ /mnt/myefs
df -hT --type nfs4
그리고 EFS를 사용할 것이기 때문에 설정 되어있는지 확인합니다.
1. EFS 파일 시스템 ID 확인: echo $EfsFsId 명령어를 통해 환경 변수 EfsFsId에 저장된 Amazon EFS 파일 시스템의 ID 값을 확인했고, fs-0be9bc03403070f1b로 확인되었습니다.
2. EFS 파일 시스템 마운트: mount -t efs -o tls $EfsFsId:/ /mnt/myefs 명령어를 사용해 EFS 파일 시스템을 /mnt/myefs 디렉토리에 마운트했습니다. 여기서 -t efs는 파일 시스템 유형으로 EFS를 지정하고, -o tls 옵션은 트래픽을 암호화하기 위해 TLS(Transport Layer Security)를 사용하겠다는 것을 나타낸다고 합니다.
3. 마운트된 파일 시스템 확인: df -hT --type nfs4 명령어를 통해 NFSv4 타입의 파일 시스템을 확인했습니다. 여기서는 EFS가 NFSv4 프로토콜을 사용하여 마운트된 것을 볼 수 있습니다. EFS은 네트워크를 통해 접근되며, 8.0E는 파일 시스템의 전체 크기를 나타내며, EFS는 확장 가능한 스토리지를 제공합니다..

해당 EFS는 AWS 콘솔에서도 확인 가능합니다!

df -hTnfsr4 타입으로 /mnt/myefs에 마운트 되어있는 것을 확인할 수 있습니다.

echo "efs file test" > /mnt/myefs/memo.txt
cat /mnt/myefs/memo.txt
rm -f /mnt/myefs/memo.txt잘 기록되고, 삭제되어 사용가능한것을 확인해보았습니다.

N1=$(kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2a -o jsonpath={.items[0].status.addresses[0].address})
N2=$(kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2b -o jsonpath={.items[0].status.addresses[0].address})
N3=$(kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2c -o jsonpath={.items[0].status.addresses[0].address})
echo "export N1=$N1" >> /etc/profile
echo "export N2=$N2" >> /etc/profile
echo "export N3=$N3" >> /etc/profile
echo $N1, $N2, $N3노드들의 정보를 각각의 변수에 저장합니다.

# 노드 보안그룹 ID 확인
NGSGID=$(aws ec2 describe-security-groups --filters Name=group-name,Values=*ng1* --query "SecurityGroups[*].[GroupId]" --output text)
aws ec2 authorize-security-group-ingress --group-id $NGSGID --protocol '-1' --cidr 192.168.1.100/32
# 워커 노드 SSH 접속
for node in $N1 $N2 $N3; do ssh ec2-user@$node hostname; done모든 프로토콜(--protocol '-1')에 대해 192.168.1.100/32 CIDR에서 오는 트래픽을 허용하보안 그룹 규칙 추가하고, 각 노드에 접속합니다 .
AWS LB/ExternalDNS, kube-ops-view 설치

kubectl get pods -A현재는 없는 구성들이 많아서 LB/ ExternalDNS, 그리고 kube-ops-view를 설치해줍니다.

# AWS LB Controller
helm repo add eks https://aws.github.io/eks-charts
helm repo update
helm install aws-load-balancer-controller eks/aws-load-balancer-controller -n kube-system --set clusterName=$CLUSTER_NAME \
--set serviceAccount.create=false --set serviceAccount.name=aws-load-balancer-controller
AWS Load Balancer controller installed! 메세지를 확인했으면 설치가 된겁니다.

# ExternalDNS
MyDomain=tipy.ee
MyDnzHostedZoneId=$(aws route53 list-hosted-zones-by-name --dns-name "${MyDomain}." --query "HostedZones[0].Id" --output text)
echo $MyDomain, $MyDnzHostedZoneId
curl -s -O https://raw.githubusercontent.com/gasida/PKOS/main/aews/externaldns.yaml
sed -i "s/0.13.4/0.14.0/g" externaldns.yaml
MyDomain=$MyDomain MyDnzHostedZoneId=$MyDnzHostedZoneId envsubst < externaldns.yaml | kubectl apply -f -본인의 도메인 네임을 변수에 저장합니다.

그리고 deployment.apps/external-dns created 메세지를 확인하면 생성이 된겁니다.

# kube-ops-view
helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 --set env.TZ="Asia/Seoul" --namespace kube-system
kubectl patch svc -n kube-system kube-ops-view -p '{"spec":{"type":"LoadBalancer"}}'
kubectl annotate service kube-ops-view -n kube-system "external-dns.alpha.kubernetes.io/hostname=kubeopsview.$MyDomain"
echo -e "Kube Ops View URL = http://kubeopsview.$MyDomain:8080/#scale=1.5"1.5배 kube-ops-view입니다.
제일 마지막에 나오는 url을 사용하여 접속하면 됩니다.

# 이미지 정보 확인
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" | tr -s '[[:space:]]' '\n' | sort | uniq -c
# eksctl 설치/업데이트 addon 확인
eksctl get addon --cluster $CLUSTER_NAME
# IRSA 확인
eksctl get iamserviceaccount --cluster $CLUSTER_NAME
1. 실행 중인 컨테이너 이미지 목록:
- 명령어는 클러스터 내 모든 네임스페이스에서 실행 중인 파드의 컨테이너 이미지를 추출하고, 이를 정렬하여 중복을 제거한 목록을 보여줍니다.
- 이미지 목록에는 AWS EKS가 관리하는 기본 애드온(예: aws-network-policy-agent, amazon-k8s-cni, coredns, kube-proxy), AWS Load Balancer Controller, ExternalDNS, 그리고 Kube-Ops-View가 포함됩니다.
- 이 정보는 클러스터의 컨테이너 이미지 버전을 확인하고, 필요한 업데이트 또는 최적화를 식별하는 데 유용합니다.
2. IAM 서비스 계정 목록:
- eksctl을 사용하여 클러스터의 IAM 서비스 계정을 조회합니다. 여기서는 aws-load-balancer-controller 서비스 계정과 관련된 IAM 역할 ARN을 확인할 수 있습니다.
- 이 정보는 클러스터에서 AWS 서비스를 사용하는 데 필요한 권한 관리를 위해 중요합니다.
3. EKS 애드온 목록:
- 클러스터에 설치된 EKS 관리형 애드온의 버전, 상태, IAM 역할, 설정 값을 포함한 세부 정보를 보여줍니다.
- 여기에는 coredns, kube-proxy, vpc-cni 애드온이 포함되어 있으며, 모두 ACTIVE 상태입니다.
- vpc-cni 애드온의 경우, 네트워크 정책을 활성화하는 설정(enableNetworkPolicy: "true")이 추가적으로 보여집니다.
- 애드온 관리는 클러스터의 기능 및 보안 유지 관리를 위해 중요합니다.
cat myeks.yaml|yh
myeks.yaml 파일의 serviceAccounts 부분은 AWS의 IRSA를 설정하는 데 사용됩니다.
IRSA는 Amazon EKS 클러스터에서 실행되는 Kubernetes 서비스 어카운트에 AWS IAM 역할을 연결할 수 있는 기능입니다. Kubernetes 파드는 AWS 리소스에 대한 세분화된 권한 관리를 할 수 있게 됩니다.
serviceAccounts 섹션
- metadata: 서비스 어카운트의 메타데이터를 정의합니다. 여기서는 name과 namespace를 지정하고 있어요. 예시에서는 aws-load-balancer-controller라는 이름을 가진 서비스 어카운트를 kube-system 네임스페이스에 생성합니다.
- wellKnownPolicies: 특정 AWS 서비스에 필요한 IAM 정책을 미리 정의된 이름으로 쉽게 연결할 수 있습니다. 예시에서는 awsLoadBalancerController: true를 설정함으로써, AWS Load Balancer Controller가 필요로 하는 IAM 권한을 자동으로 부여받게 됩니다. 이는 EKS 클러스터에서 AWS Application Load Balancer(ALB) 또는 Network Load Balancer(NLB)를 관리하는 데 필요한 권한을 포함합니다.
IRSA 작동 원리:
1. IAM 역할 생성: EKS 클러스터를 생성하거나 업데이트할 때, eksctl은 wellKnownPolicies에 명시된 정책을 바탕으로 필요한 IAM 역할을 생성합니다.
2. OIDC Identity Provider 구성: withOIDC: true 설정을 통해, EKS 클러스터에 OIDC(OpenID Connect) 아이덴티티 프로바이더를 구성합니다. 이는 AWS IAM과 Kubernetes 서비스 어카운트 간의 신뢰 관계를 설정하는 데 사용됩니다.
3. 서비스 어카운트에 IAM 역할 연결: 생성된 IAM 역할은 서비스 어카운트의 어노테이션을 통해 해당 서비스 어카운트에 연결됩니다. 이 과정은 eksctl이 자동으로 처리합니다.
4. AWS 리소스에 대한 접근: 해당 서비스 어카운트를 사용하여 생성된 파드는 IAM 역할에 정의된 권한을 통해 AWS 리소스에 접근할 수 있습니다. 이를 통해, 파드는 필요한 AWS 서비스를 안전하게 사용할 수 있게 됩니다.
IRSA를 사용하면, 각 Kubernetes 서비스 어카운트마다 필요한 최소한의 AWS 권한을 정밀하게 부여할 수 있어, 보안을 강화할 수 있습니다. 예시에서는 AWS Load Balancer Controller가 AWS의 로드 밸런서를 관리할 수 있는 권한을 부여받게 됩니다.
스토리지 이해
기본 컨테이너 환경의 임시 파일시스템 사용
curl -s -O https://raw.githubusercontent.com/gasida/PKOS/main/3/date-busybox-pod.yaml
cat date-busybox-pod.yaml | yh
kubectl apply -f date-busybox-pod.yaml

busybox 이미지를 기반으로 하는 Pod를 생성했습니다. 이 Pod는 무한 루프를 돌면서 현재 시간을 /home/pod-out.txt 파일에 기록합니다.
kubectl get pod,pvc
현재는 busybox이미지 기반 파드만 있다.
kubectl exec busybox -- tail -f /home/pod-out.txt
현재 기록되있는 데이터들을 다음과 같다.
kubectl delete pod busybox
kubectl apply -f date-busybox-pod.yaml
해당 파드를 삭제한 후 다시 생성하고
kubectl exec busybox -- tail -f /home/pod-out.txt
로그를 확인하면 그 전 시간부터 찍혀있던 데이터들이 사라진것을 알 수 있다. 이 임시 볼륨은은 컨테이너에 종속적이기 때문에, 파드가 삭제되어서 그 전 데이터는 날아갔기 때문이다.
호스트 Path 를 사용하는 PV/PVC : local-path-provisioner 스트리지 클래스 배포
curl -s -O https://raw.githubusercontent.com/rancher/local-path-provisioner/master/deploy/local-path-storage.yaml
kubectl apply -f local-path-storage.yaml
kubectl get sc
kubectl get sc local-path
Kubernetes 클러스터에 Local Path Provisioner를 설치하고, 이를 통해 로컬 스토리지를 사용할 수 있는 local-path 스토리지 클래스(StorageClass)를 생성했습니다. Local Path Provisioner는 Rancher에서 제공하는 경량 스토리지 프로비저너로, 노드의 로컬 스토리지를 동적으로 프로비저닝하는 데 사용됩니다.
스토리지 클래스 확인
kubectl get sc 명령어를 통해 사용 가능한 스토리지 클래스를 확인했습니다. 여기서 gp2는 AWS EBS 볼륨을 동적으로 프로비저닝하는 기본 스토리지 클래스이며, local-path는 방금 설치한 Local Path Provisioner에 의해 관리되는 스토리지 클래스입니다.
local-path 스토리지 클래스 상세 정보 확인
kubectl get sc local-path 명령어를 통해 local-path 스토리지 클래스의 상세 정보를 확인했습니다. 여기서 rancher.io/local-path는 프로비저너, Delete는 PVC(PersistentVolumeClaim)가 삭제될 때 볼륨의 재활용 정책, WaitForFirstConsumer는 볼륨 바인딩 모드를 나타냅니다. 이 모드는 PVC가 사용될 파드가 스케줄링될 노드에 기반하여 볼륨 바인딩과 동적 프로비저닝이 발생하게 합니다.
PV/PVC 를 사용하는 파드 생성
curl -s -O https://raw.githubusercontent.com/gasida/PKOS/main/3/localpath1.yaml
cat localpath1.yaml | yh
kubectl apply -f localpath1.yaml
kubectl get pvc
kubectl describe pvc
localpath-claim PersistentVolumeClaim (PVC)은 현재 Pending 상태입니다. kubectl describe pvc의 출력에서 확인할 수 있듯이, 이 PVC는 WaitForFirstConsumer 모드로 설정되어 있어서, 실제로 사용하는 파드가 생성되기 전까지 바인딩되는 볼륨을 대기하고 있습니다.
이는 local-path StorageClass의 volumeBindingMode가 WaitForFirstConsumer로 설정되었기 때문입니다.
파드 생성
curl -s -O https://raw.githubusercontent.com/gasida/PKOS/main/3/localpath2.yaml
cat localpath2.yaml | yh
kubectl apply -f localpath2.yaml
파드 확인
kubectl get pod,pv,pvc
kubectl exec -it app -- tail -f /data/out.txt
localpath2.yaml 파일로 app라는 이름의 Pod를 생성했고, 이 Pod는 localpath-claim이라는 PersistentVolumeClaim(PVC)을 사용하여 로컬 스토리지에 접근합니다. 이 파일 내의 컨테이너는 5초마다 현재 UTC 시간을 /data/out.txt 파일에 기록하는 스크립트를 실행합니다.
1. persistentVolumeClaim을 통해 특정 PersistentVolumeClaim(PVC)에 바인딩됩니다. 이 경우 claimName: localpath-claim은 이 볼륨이 localpath-claim이라는 이름의 PVC에 바인딩되어야 함을 나타냅니다. PVC를 통해 동적으로 또는 미리 생성된 PersistentVolume(PV)에 연결됩니다.
2. volumeMounts 섹션: 컨테이너 수준에서 볼륨을 마운트하는 방법을 정의합니다. 여기서는 app 컨테이너가 persistent-storage 볼륨을 /data라는 경로에 마운트하도록 설정되어 있습니다. 이 마운트 경로는 컨테이너 내에서 볼륨에 접근하기 위한 파일 시스템의 위치를 나타냅니다.
작동 원리
- Pod가 시작되면, localpath-claim PVC를 사용하여 요청된 스토리지에 대한 PV가 할당됩니다. 이 PV는 로컬 또는 외부 스토리지에 있을 수 있습니다.
- 할당된 PV는 persistent-storage 볼륨을 통해 Pod에 연결되며, app 컨테이너는 이 볼륨을 /data 경로에 마운트하여 사용합니다.
- app 컨테이너는 무한 루프를 돌면서 현재 시간을 /data/out.txt 파일에 기록합니다. 이 파일은 PV에 저장되므로, Pod가 삭제되더라도 local-path 스토리지 클래스의 Reclaim Policy 설정에 따라 데이터의 보존 여부가 결정됩니다.
`

kubectl describe pv # Node Affinity 확인Node Affinity부분은 PersistentVolume(PV)이 특정 노드에 바인딩되어 사용될 수 있도록 설정하는 Kubernetes의 기능입니다. 이는 특히 로컬 스토리지와 같이 노드에 종속적인 리소스를 사용할 때 중요합니다.Node Affinity`를 사용함으로써, Kubernetes 스케줄러는 PV를 요구하는 Pod가 해당 노드에만 배치되도록 보장합니다.
Node Affinity 설명
- Required Terms: 이 섹션은 PV가 바인딩될 수 있는 노드의 조건을 정의합니다. 여기서는 특정 키(kubernetes.io/hostname)에 대한 요구사항을 명시하고 있으며, 이 키의 값이 주어진 노드 이름(ip-192-168-3-85.ap-northeast-2.compute.internal)과 일치해야 합니다.
- kubernetes.io/hostname in [ip-192-168-3-85.ap-northeast-2.compute.internal]: 이 표현은 PV가 ip-192-168-3-85.ap-northeast-2.compute.internal이라는 호스트 이름을 가진 노드에만 배치될 수 있음을 나타냅니다. 즉, 이 PV는 오직 해당 노드에서만 사용될 수 있으며, 이 노드에 스케줄링된 Pod만이 이 PV를 사용할 수 있습니다.
PersistentVolume (PV)의 Node Affinity 부분은 해당 PV가 특정 노드에만 바인딩되어 사용될 수 있도록 지정하는 설정입니다. 이 설정은 주로 로컬 스토리지를 사용하는 경우에 중요한 역할을 합니다. 로컬 스토리지는 물리적으로 한 노드에 위치해 있으므로, 해당 스토리지를 사용하는 파드도 동일한 노드에 스케줄링되어야 합니다.
for node in $N1 $N2 $N3; do ssh ec2-user@$node tree /opt/local-path-provisioner; done
Node Affinity 상세 설명
- local.path.provisioner/selected-node 어노테이션: 이 어노테이션은 Local Path Provisioner가 PV를 생성할 때 선택한 노드의 이름을 나타냅니다. 예를 들어, ip-192-168-2-11.ap-northeast-2.compute.internal은 PV가 위치할 대상 노드입니다.
- Node Affinity 섹션: 이 섹션은 PV가 특정 조건을 만족하는 노드에만 바인딩될 수 있도록 Kubernetes에 지시합니다. 예제에서는 kubernetes.io/hostname 레이블이 ip-192-168-2-11.ap-northeast-2.compute.internal인 노드에만 PV가 바인딩될 수 있습니다.
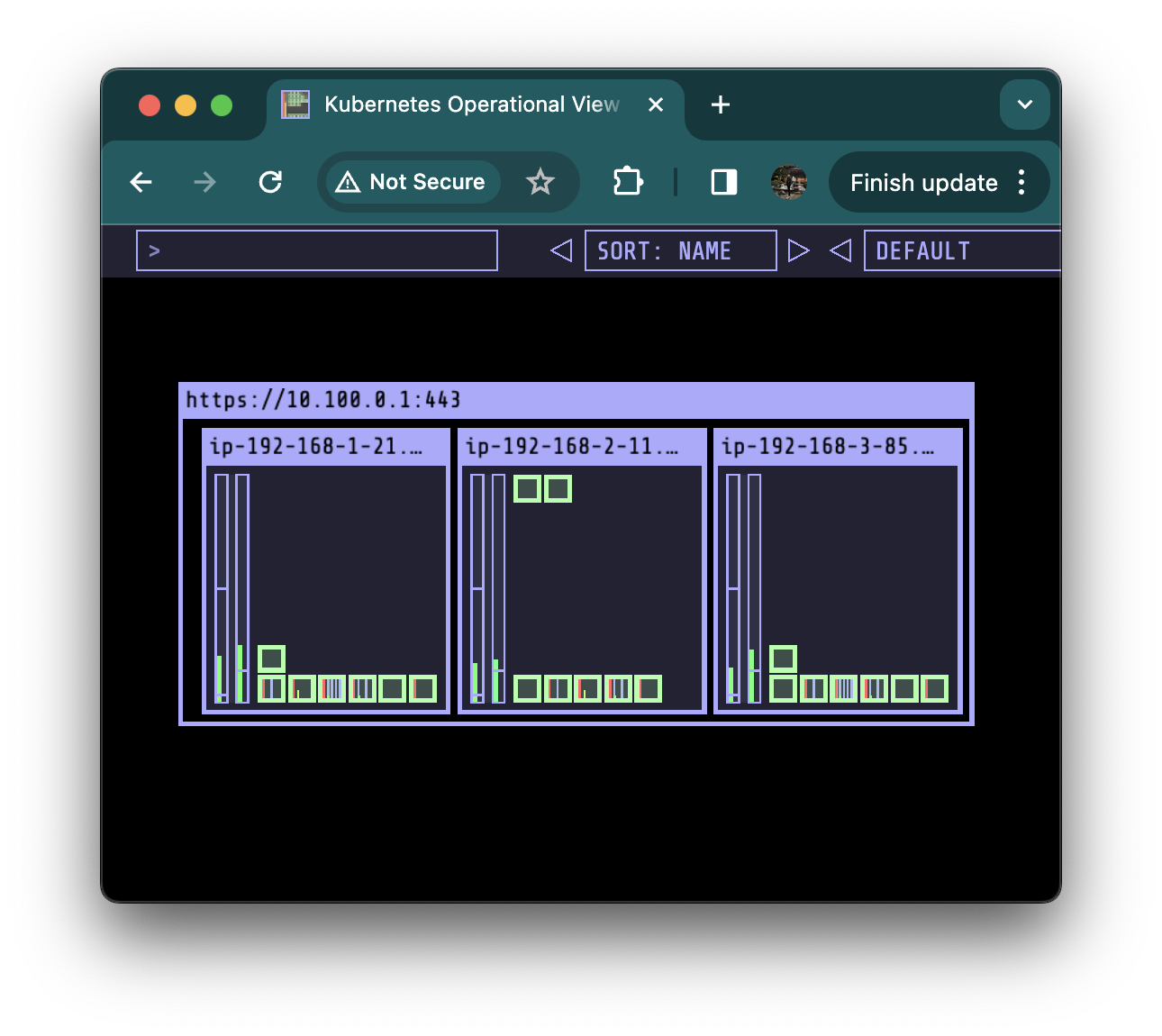
kube-ops-view에서도 해당 노드에 파드가 있는것을 확인 가능합니다.
실제 작동 방식
여러분이 실행한 ssh 명령어로 각 노드에서 /opt/local-path-provisioner 디렉토리를 확인했을 때, 오직 하나의 노드(ip-192-168-2-11.ap-northeast-2.compute.internal)에서만 pvc-6466016f-447b-49de-8a0d-7d550ad12bda_default_localpath-claim 디렉토리와 그 안의 out.txt 파일을 찾을 수 있었습니다. 이는 Node Affinity 설정이 정상적으로 작동하여, 해당 PV와 연결된 스토리지가 오직 지정된 노드에만 위치하도록 보장한 결과입니다.
파드 삭제
kubectl delete pod app
kubectl get pod,pv,pvc
kubectl get pod,pv,pvc 명령으로 Pod, PV, PVC의 상태를 확인했을 때, app Pod는 더 이상 목록에 나타나지 않지만, PV와 PVC는 여전히 Bound 상태로 나타납니다. 이는 PVC와 PV 간의 바인딩이 유지되고 있음을 나타냅니다.
for node in $N1 $N2 $N3; do ssh ec2-user@$node tree /opt/local-path-provisioner; done
for node in $N1 $N2 $N3; do ssh ec2-user@$node tree /opt/local-path-provisioner; done 명령으로 각 노드의 /opt/local-path-provisioner 디렉토리를 확인했을 때, 해당 PV가 사용하는 로컬 스토리지 경로에 out.txt 파일이 여전히 존재합니다.
kubectl apply -f localpath2.yaml
kubectl exec -it app -- head /data/out.txt
kubectl exec -it app -- tail -f /data/out.txt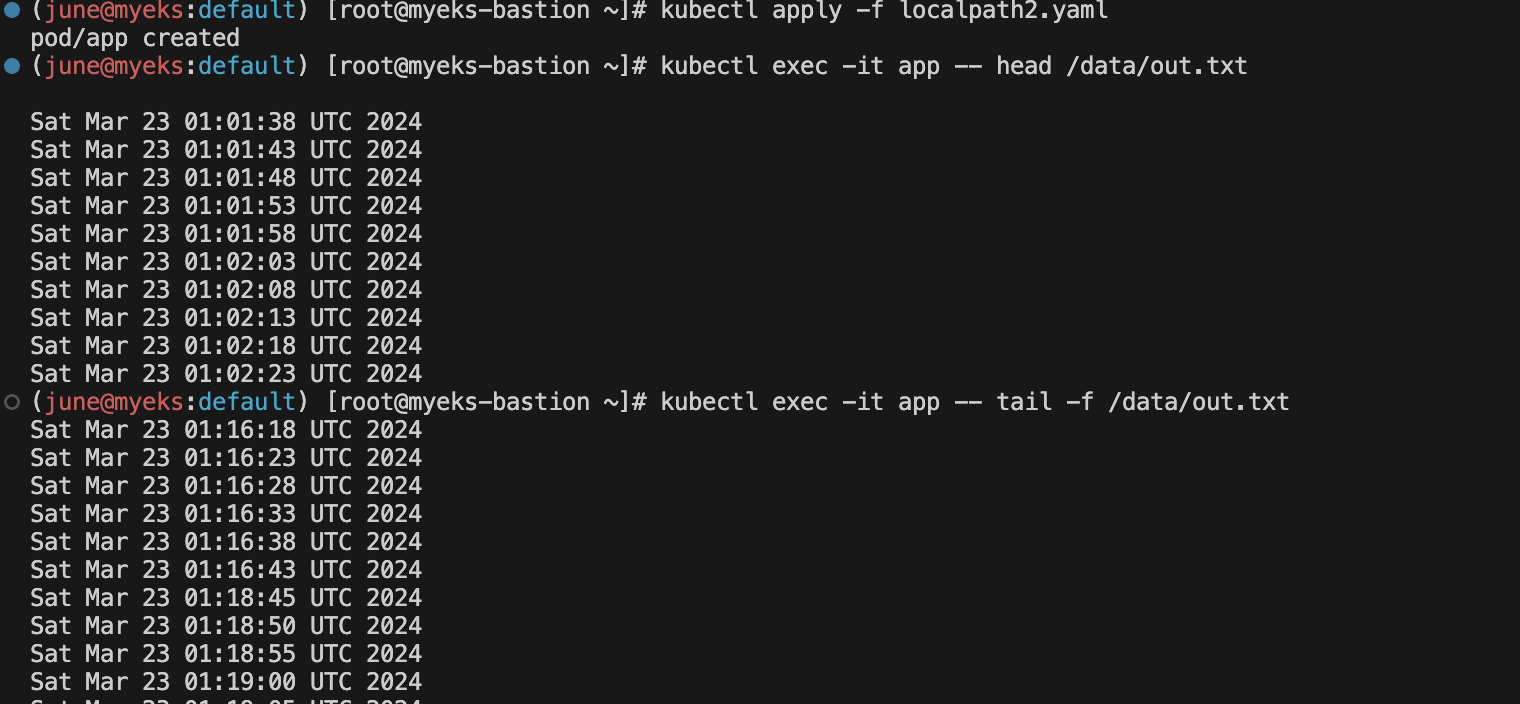
kubectl apply -f localpath2.yaml 명령으로 app Pod를 다시 생성했습니다. 이 Pod는 동일한 PVC localpath-claim을 사용하여 로컬 스토리지에 접근합니다.
kubectl exec -it app -- tail -f /data/out.txt 명령으로 app 컨테이너 내부에서 out.txt 파일의 내용을 실시간으로 확인했습니다. Pod 삭제와 재생성 사이에 기록된 시간 데이터가 유지되고 있음을 확인할 수 있습니다.
Pod 삭제: kubectl delete pod app 명령을 사용해 app Pod를 삭제했습니다. 이 과정은 Pod를 종료하고 제거하지만, PV나 PVC에는 영향을 주지 않습니다. Pod와 PV/PVC는 독립적인 리소스로, Pod의 삭제가 바로 PV나 PVC를 삭제하지는 않습니다.
PVC 삭제: kubectl delete pvc localpath-claim 명령을 통해 localpath-claim PVC를 삭제했습니다. PVC가 삭제되면, 그와 연관된 PV의 Reclaim Policy에 따라 PV의 처리가 달라집니다. 여기서는 Reclaim Policy가 Delete로 설정되어 있기 때문에, PVC 삭제 시 연관된 PV와 그에 저장된 데이터도 함께 삭제됩니다.
PV 상태 확인: kubectl get pv 명령을 실행한 결과, 더 이상 사용 가능한 PV가 없음을 확인할 수 있습니다. 이는 PVC 삭제와 함께 연관된 PV가 시스템에서 제거되었음을 나타냅니다.
노드의 로컬 스토리지 확인: for node in $N1 $N2 $N3; do ssh ec2-user@$node tree /opt/local-path-provisioner; done 명령으로 각 노드의 /opt/local-path-provisioner 디렉토리를 확인했을 때, 더 이상 파일이나 디렉토리가 존재하지 않음을 확인할 수 있습니다. 이는 PV 삭제 과정에서 로컬 스토리지에 저장된 데이터가 함께 삭제되었음을 의미합니다.
삭제
# 파드와 PVC 삭제
kubectl delete pod app
kubectl get pv,pvc
kubectl delete pvc localpath-claim삭제는 위 명령으로 합니다.
kubectl get pv
for node in $N1 $N2 $N3; do ssh ec2-user@$node **tree /opt/local-path-provisioner**; done
삭제되었는지 확인합니다.
AWS EBS Controller

Kubernetes의 스토리지 클래스와 AWS의 EBS 볼륨을 연동하는 과정을 보여주고 있습니다.
각 번호는 볼륨 프로비저닝의 각 단계를 나타내는데, CSI (Container Storage Interface)를 사용하고 있습니다.
1. API 서버 감시 (Watch): CSI 컨트롤러가 쿠버네티스 API 서버를 감시하고 있습니다. PersistentVolumeClaim (PVC) 같은 스토리지 관련 요청이 생기면 반응합니다.
2. 조치 (Action): PVC가 생성되면 CSI 컨트롤러가 이를 감지하고 AWS API를 호출해 EBS 볼륨을 준비합니다.
3. 생성 (Provisioning): AWS에서 EBS 볼륨을 생성하고 준비합니다. 이 볼륨은 나중에 파드가 사용할 수 있도록 준비되는 스토리지 공간입니다.
4. 마운트 요청 (Mount Request): EBS 볼륨이 준비되면 쿠버네티스의 kubelet에게 마운트를 요청합니다.
5. kubelet 마운트: kubelet은 CSI 노드 플러그인에게 실제로 노드에 EBS 볼륨을 연결하라고 요청합니다.
6. CSI 노드 마운트: CSI 노드 플러그인이 EBS 볼륨을 파드가 실행 중인 노드에 실제로 마운트하고, 그 결과 파드는 EBS 볼륨을 사용할 수 있게 돼요.
이 과정을 통해 파드는 필요한 데이터를 저장하거나 불러올 수 있는 EBS 볼륨에 접근할 수 있게 됩니다. 이 모든 것이 자동으로 이루어져 사용자는 PVC를 요청하기만 하면 되고, 나머지는 쿠버네티스와 AWS가 처리해줍니다.
IRSA 설정
eksctl create iamserviceaccount \
--name ebs-csi-controller-sa \
--namespace kube-system \
--cluster ${CLUSTER_NAME} \
--attach-policy-arn arn:aws:iam::aws:policy/service-role/AmazonEBSCSIDriverPolicy \
--approve \
--role-only \
--role-name AmazonEKS_EBS_CSI_DriverRole
IRSA를 설정합니다. (전 이미 만들어서 새로 생기지 않습니다.)
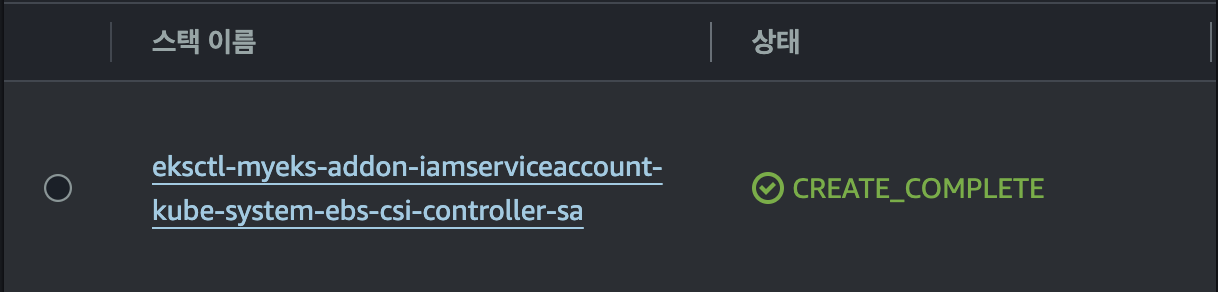
cloudformation에서 스택으로도 확인 가능합니다.
eksctl get iamserviceaccount --cluster myeks
ebs-csi-controller-sa로 생긴것을 확인할 수 있습니다.
Amazon EBS CSI driver addon 추가 & 확인
eksctl create addon --name aws-ebs-csi-driver --cluster ${CLUSTER_NAME} --service-account-role-arn arn:aws:iam::${ACCOUNT_ID}:role/AmazonEKS_EBS_CSI_DriverRole --force
kubectl get sa -n kube-system ebs-csi-controller-sa -o yaml | head -5
추가해줍니다.
kubectl get pod -n kube-system -l 'app in (ebs-csi-controller,ebs-csi-node)'
kubectl get deploy,ds -l=app.kubernetes.io/name=aws-ebs-csi-driver -n kube-system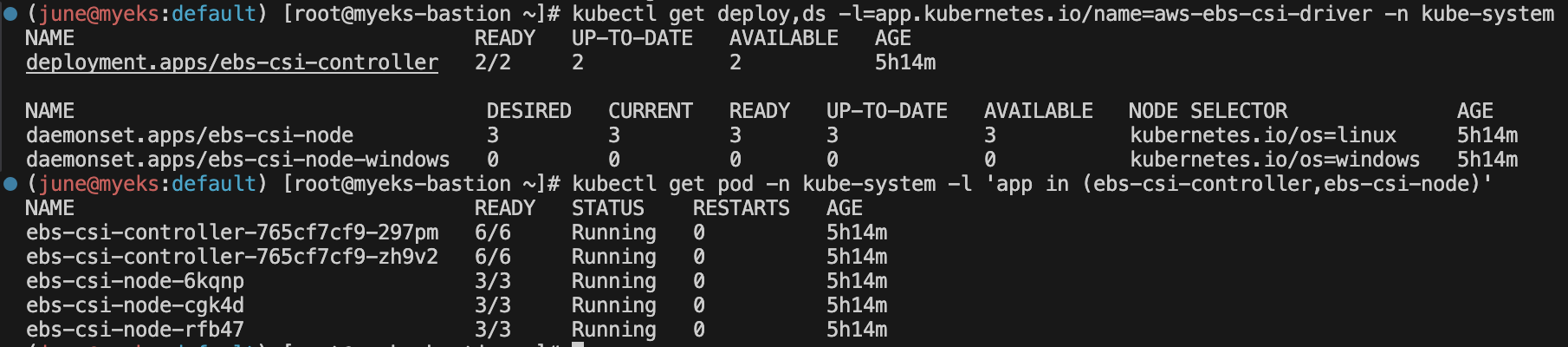
ebs-csi-node-windows는 사용하는 노드 운영체제가 윈도우일때 활성화 되지만, 지금은 리눅스라서 0이 맞습니다.
그리고 컨트롤러에는 6개의 컨테이너가 있습니다.
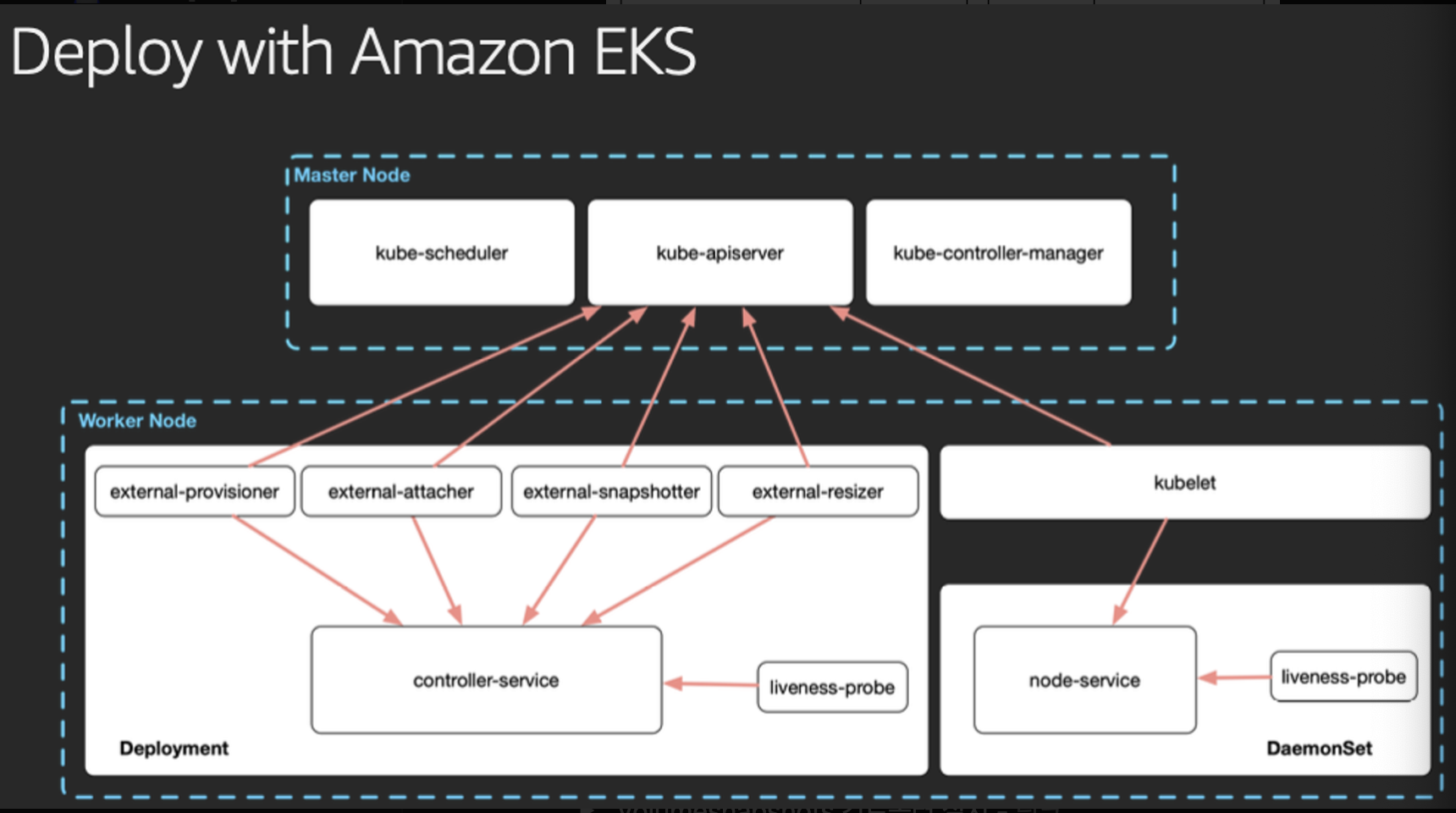
Master Node
여기에는 kube-scheduler, kube-apiserver, 그리고 kube-controller-manager와 같은 쿠버네티스의 핵심 컨트롤 플레인 컴포넌트들이 포함되어 있습니다. 이 컴포넌트들은 클러스터의 리소스 스케줄링, API 요청 처리, 전반적인 클러스터 상태 관리 등을 담당합니다.
Worker Node
워커 노드들은 실제로 컨테이너화된 애플리케이션들이 실행되는 곳입니다. kubelet은 이 노드들 위에서 돌아가며 컨테이너의 생명주기를 관리합니다.
CSI (Container Storage Interface) Components:
- external-provisioner: 동적 볼륨 프로비저닝을 관리합니다. 새로운 스토리지 요청이 있을 때 적절한 볼륨을 생성합니다.
- external-attacher: 볼륨을 파드에 연결(attach)하는 작업을 처리합니다.
- external-snapshotter: 볼륨 스냅샷을 생성하고 관리합니다. 이는 볼륨의 시점 복제본을 만드는 기능입니다.
- external-resizer: 볼륨의 크기를 조정하는 작업을 담당합니다.
위의 CSI 컴포넌트들은 스토리지 관련 작업을 쿠버네티스 클러스터 외부의 시스템과 통합하여 처리합니다.
- Deployment & DaemonSet:
- Deployment: 여러 개의 레플리카로 구성된 애플리케이션을 배포하고 관리합니다.
- DaemonSet: 클러스터의 모든 노드(또는 일부 노드)에 특정 애플리케이션을 실행하기 위해 사용됩니다.
- liveness-probe: 파드의 컨테이너가 정상적으로 작동하고 있는지 검사하는 데 사용됩니다. 문제가 감지되면 kubelet에 의해 컨테이너가 재시작됩니다.
gp3 스토리지 클래스 생성

cat <<EOT > gp3-sc.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: gp3
allowVolumeExpansion: true
provisioner: ebs.csi.aws.com
volumeBindingMode: WaitForFirstConsumer
parameters:
type: gp3
#iops: "5000"
#throughput: "250"
allowAutoIOPSPerGBIncrease: 'true'
encrypted: 'true'
fsType: xfs # 기본값이 ext4
EOTgp3 스토리지 클래스 생성을 해줍니다 (저는 이미 만들어서 새롭게 생성 안됩니다.)
kubectl apply -f gp3-sc.yaml
kubectl get sc
kubectl describe sc gp3 | grep Parameters
(저는 이미 만들어서 새롭게 생성 안됩니다.)
파라미터에서 위에 파일에 넣은 값들이 잘 들어갔는지 확인해줍니다.
while true; do aws ec2 describe-volumes --filters Name=tag:ebs.csi.aws.com/cluster,Values=true --query "Volumes[].{VolumeId: VolumeId, VolumeType: VolumeType, InstanceId: Attachments[0].InstanceId, State: Attachments[0].State}" --output text; date; sleep 1; done
볼륨이 어디에 붙었는지를 한 터미널을 열어서 지속적으로 감시를 해줍니다.
pvc생성
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: ebs-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 4Gi
storageClassName: gp3
EOTpvc 생성을 위해서 파일을 생성 해줍니다.
kubectl apply -f awsebs-pvc.yaml
kubectl get pvc,pv그리고 배포 후 pvc와 Pv의 상태를 확인합니다.

pending인 상태는 파드를 기다리고있기 때문입니다.
파드 생성
cat <<EOT > awsebs-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: app
spec:
terminationGracePeriodSeconds: 3
containers:
- name: app
image: centos
command: ["/bin/sh"]
args: ["-c", "while true; do echo \$(date -u) >> /data/out.txt; sleep 5; done"]
volumeMounts:
- name: persistent-storage
mountPath: /data
volumes:
- name: persistent-storage
persistentVolumeClaim:
claimName: ebs-claim
EOT위 파일로 파드를 생성해줍니다.
kubectl apply -f awsebs-pod.yaml
파드를 바로 배포해줍니다.

바로 배포를 해줍니다. 파드 배포 후 볼륨을 attached로 바로 확인하는 것을 볼 수 있습니다.

PVC, 파드 확인
kubectl get pvc,pv,pod
kubectl get VolumeAttachment
어느 노드에 볼륨이 잘 붙어있는지 확인할 수 있습니다.
kubectl get pv -o yaml | yh
pv를 상세히 확인할 수 있습니다.
여기에서 node affinity를 자세히 보려고합니다.
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: topology.ebs.csi.aws.com/zone
operator: In
values:
- ap-northeast-2btopology가 ap-northeast-2b인 노드에만 붙도록 되어있습니다.
다른 가용영역은 해당이 안됩니다 .
kubectl df-pv
다음 명령어로 편리하게 Pv의 정보를 확인 가능합니다.
볼륨 크기 증가

aws 볼륨에서 확인할 수 있듯이 현재 볼륨의 크기는 4G입니다. 볼륨상태는 사용 중 입니다.
kubectl get pvc ebs-claim -o jsonpath={.spec.resources.requests.storage} ; echo
kubectl get pvc ebs-claim -o jsonpath={.status.capacity.storage} ; echo
kubectl patch pvc ebs-claim -p '{"spec":{"resources":{"requests":{"storage":"10Gi"}}}}'
다음 명령으로 용량을 10G로 늘리는 요청을 해봅니다 .

콘솔에서 같은 볼류에 대해서 확인을해보면, 크기가 10G로 늘어난것을 확인할 수 있습니다.
다만 볼륨상태가 optimizing이 100퍼센트가 되어야 10기가 온전히 사용가능한데, 따로 건드릴건 없고 기다리면 됩니다.
클린업
kubectl delete pod app & kubectl delete pvc ebs-claim
AWS Volume SnapShots Controller
# Install Snapshot CRDs
curl -s -O https://raw.githubusercontent.com/kubernetes-csi/external-snapshotter/master/client/config/crd/snapshot.storage.k8s.io_volumesnapshots.yaml
curl -s -O https://raw.githubusercontent.com/kubernetes-csi/external-snapshotter/master/client/config/crd/snapshot.storage.k8s.io_volumesnapshotclasses.yaml
curl -s -O https://raw.githubusercontent.com/kubernetes-csi/external-snapshotter/master/client/config/crd/snapshot.storage.k8s.io_volumesnapshotcontents.yaml
kubectl apply -f snapshot.storage.k8s.io_volumesnapshots.yaml,snapshot.storage.k8s.io_volumesnapshotclasses.yaml,snapshot.storage.k8s.io_volumesnapshotcontents.yaml
kubectl get crd | grep snapshot
kubectl api-resources | grep snapshot
# Install Common Snapshot Controller
curl -s -O https://raw.githubusercontent.com/kubernetes-csi/external-snapshotter/master/deploy/kubernetes/snapshot-controller/rbac-snapshot-controller.yaml
curl -s -O https://raw.githubusercontent.com/kubernetes-csi/external-snapshotter/master/deploy/kubernetes/snapshot-controller/setup-snapshot-controller.yaml
kubectl apply -f rbac-snapshot-controller.yaml,setup-snapshot-controller.yaml
kubectl get deploy -n kube-system snapshot-controller
kubectl get pod -n kube-system -l app=snapshot-controller
# Install Snapshotclass
curl -s -O https://raw.githubusercontent.com/kubernetes-sigs/aws-ebs-csi-driver/master/examples/kubernetes/snapshot/manifests/classes/snapshotclass.yaml
kubectl apply -f snapshotclass.yaml
kubectl get vsclass # 혹은 volumesnapshotclasses위 커멘드라인을 따라서 설치를 해줍니다.
# PVC 생성
kubectl apply -f awsebs-pvc.yaml
# 파드 생성
kubectl apply -f awsebs-pod.yaml
kubectl exec app -- tail -f /data/out.txt
파일에 내용이 추가되는지 확인합니다.

스냅샷 파드에서 연결된 Pvc에서 생성된 pv 볼륨입니다.

curl -s -O https://raw.githubusercontent.com/gasida/PKOS/main/3/ebs-volume-snapshot.yaml
cat ebs-volume-snapshot.yaml | yh
kubectl apply -f ebs-volume-snapshot.yaml
소스 부분이 Pv를 지정하는것이다.
해당 Pvc에서 만들어진 Pv가 스냅샷으로 지정이 됩니다.

AWS콘솔에서 해당 스냅샷을 확인 가능합니다.
이 이중 저장 체계가 안전하다.
app & pvc 제거 : 강제로 장애 재현
kubectl delete pod app && kubectl delete pvc ebs-claim
장애의 내용은 다음과 같습니다.
파드와 Pvc를 삭제합니다. pvc가 삭제됨에 따라 Pvc에 의해 생성이 되었던 Pv도 삭제가 됩니다.
kubectl get pod,pvc
의도대로 다 잘 날아갔는것 확인했습니다.

aws 콘솔에서도 해당 볼류은 사라진것 확인했습니다.
스냅샷을 사용하여 복원
cat <<EOT > ebs-snapshot-restored-claim.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: ebs-snapshot-restored-claim
spec:
storageClassName: gp3
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 4Gi
dataSource:
name: ebs-volume-snapshot
kind: VolumeSnapshot
apiGroup: snapshot.storage.k8s.io
EOT
위 Pvc를 위한 파일을 생성해줍니다.
dataSource:
name: ebs-volume-snapshot
kind: VolumeSnapshot
apiGroup: snapshot.storage.k8s.iodataSource 부분을 확인하면
볼륨 스냅샷을 지정해놨는데, 이 볼륨 스냅샷을 기준으로 pvc를 만든다고 생각하면 됩니다 .
cat ebs-snapshot-restored-claim.yaml | yh
kubectl apply -f ebs-snapshot-restored-claim.yaml
스냅샷의 이름을 그대로 사용해서 pvc로 지정하고 바로 배포를 시켜줍니다.
kubectl get pvc,pv
현재 pvc가 펜딩인것을 확인할 수 있었습니다.
파드를 생성하면 동작하겠군요
curl -s -O https://raw.githubusercontent.com/gasida/PKOS/main/3/ebs-snapshot-restored-pod.yaml
cat ebs-snapshot-restored-pod.yaml | yh
파드 파일을 다운받아줍니다.
kubectl apply -f ebs-snapshot-restored-pod.yaml
파드를 배포 시킵니다.
kubectl get pvc,pv
다시 pvc와 pv를 확인하면 Pv가 무마운트 된 것 확인할 수 있습니다.
kubectl exec app -- cat /data/out.txt
저장되는 데이터들을 읽어보면 원래는 5초 간격으로 확인하지만, 스냅샷을 Pvc로 연결하는동안의 시간이 뜨는것을 확인할 수 있습니다.
https://popappend.tistory.com/113
https://jerryljh.tistory.com/42
https://backube.github.io/snapscheduler/
그렇다면 장애시에도 정기적으로 스냅샷을 생성하고 적용가능하면 최대한 손실이 없겠다 싶어서 참고할 수 있는 링크 입니다.
클린업
kubectl delete pod app && kubectl delete pvc ebs-snapshot-restored-claim && kubectl delete volumesnapshots ebs-volume-snapshot
클린업은 다음 커멘드로 합니다.
AWS EFS Controller

기본 설정
# EFS 정보 확인
aws efs describe-file-systems --query "FileSystems[*].FileSystemId" --output text
# IAM 정책 생성
curl -s -O https://raw.githubusercontent.com/kubernetes-sigs/aws-efs-csi-driver/master/docs/iam-policy-example.json
aws iam create-policy --policy-name AmazonEKS_EFS_CSI_Driver_Policy --policy-document file://iam-policy-example.json
# IRSA 설정 : 고객관리형 정책 AmazonEKS_EFS_CSI_Driver_Policy 사용
eksctl create iamserviceaccount \
--name efs-csi-controller-sa \
--namespace kube-system \
--cluster ${CLUSTER_NAME} \
--attach-policy-arn arn:aws:iam::${ACCOUNT_ID}:policy/AmazonEKS_EFS_CSI_Driver_Policy \
--approve
# IRSA 확인
kubectl get sa -n kube-system efs-csi-controller-sa -o yaml | head -5
eksctl get iamserviceaccount --cluster myeks위 커멘드로 IRSA까지 설정을 해줍니다.


AWS Cloudformation에서도 IRSA 생성 스택 확인이 가능합니다.
EFS Controller 설치
helm repo add aws-efs-csi-driver https://kubernetes-sigs.github.io/aws-efs-csi-driver/
helm repo update
helm upgrade -i aws-efs-csi-driver aws-efs-csi-driver/aws-efs-csi-driver \
--namespace kube-system \
--set image.repository=602401143452.dkr.ecr.${AWS_DEFAULT_REGION}.amazonaws.com/eks/aws-efs-csi-driver \
--set controller.serviceAccount.create=false \
--set controller.serviceAccount.name=efs-csi-controller-sa
helm차트를 사용해서 EFS Controller를 설치해줍니다.
확인
helm list -n kube-system
kubectl get pod -n kube-system -l "app.kubernetes.io/name=aws-efs-csi-driver,app.kubernetes.io/instance=aws-efs-csi-driver"

설치가 제대로 되었다면, myeks-EFS라는 이름으로 AWS 콘솔에서 확인이 가능합니다.
watch 'kubectl get sc efs-sc; echo; kubectl get pv,pvc,pod'
터미널을 하나 더 생성해서 위 명령어로 watch를 걸어줍니다.
git clone https://github.com/kubernetes-sigs/aws-efs-csi-driver.git /root/efs-csi
cd /root/efs-csi/examples/kubernetes/multiple_pods/specs && tree
다른 터미널에서는 실습하기 위한 코드를 다운받습니다.
해당경로에 저런 파일들이 있습니다.
EFS 스토리지클래스 생성 및 확인
cat storageclass.yaml | yh
kubectl apply -f storageclass.yaml
kubectl get sc efs-sc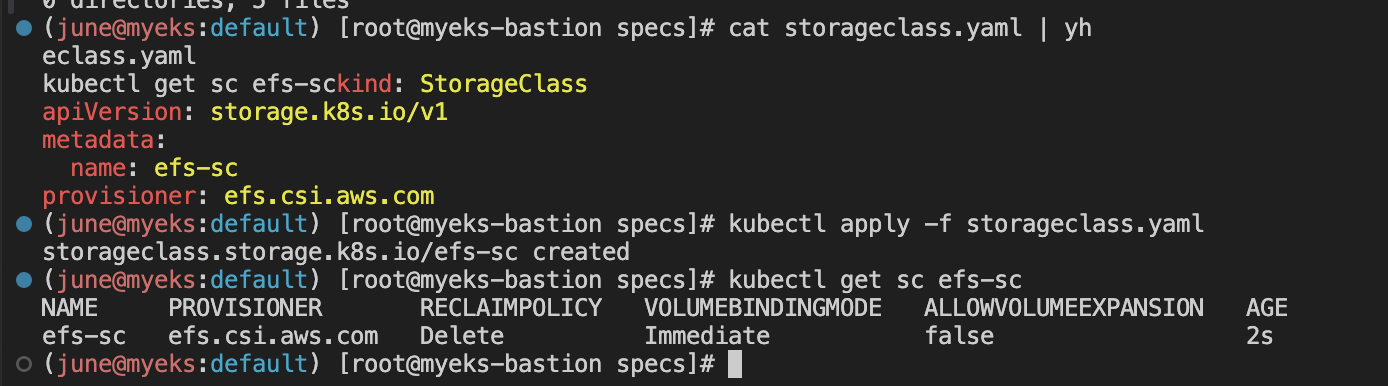
이렇게 EFS 스토리지 클래스를 생성해줍니다.

위에 watch로 걸어놓은것에서 볼륨이 바로 감지가 되네요
EfsFsId=$(aws efs describe-file-systems --query "FileSystems[*].FileSystemId" --output text)
sed -i "s/fs-4af69aab/$EfsFsId/g" pv.yaml
pv를 만들 때 하나 신경써줘야할것은 내 EFS ID를 넣어줘야 합니다.
cat pv.yaml | yh

pv의 내용을 확인해줍니다.
특히 efs의 id를 AWS 콘솔에서 확인한 id값이랑 같은지 확인해줍니다.
kubectl apply -f pv.yaml
kubectl get pv; kubectl describe pv
Pv를 배포 해줍니다.

watch로 걸어놓은 것에서 persistentvolume/efs-pv로 바로 감지가 되네요
PVC생성
cat claim.yaml | yh
kubectl apply -f claim.yaml
kubectl get pvc
pvc를 배포해줍니다.

Watch로 걸어놓은것에서도 persistentvolumeclaim/efs-claim라는 이름의 Pvc가 확인됩니다.
cat pod1.yaml pod2.yaml | yh
pod1과 pod2의 내용을 확인해줍니다.
kubectl apply -f pod1.yaml,pod2.yaml
파드를 배포 해줍니다.

Watch로 걸어놓은것에서 Pod1과 pod2가 생성된것을 확인했습니다.
kubectl get pods
kubectl exec -ti app1 -- sh -c "df -hT -t nfs4"
kubectl exec -ti app2 -- sh -c "df -hT -t nfs4"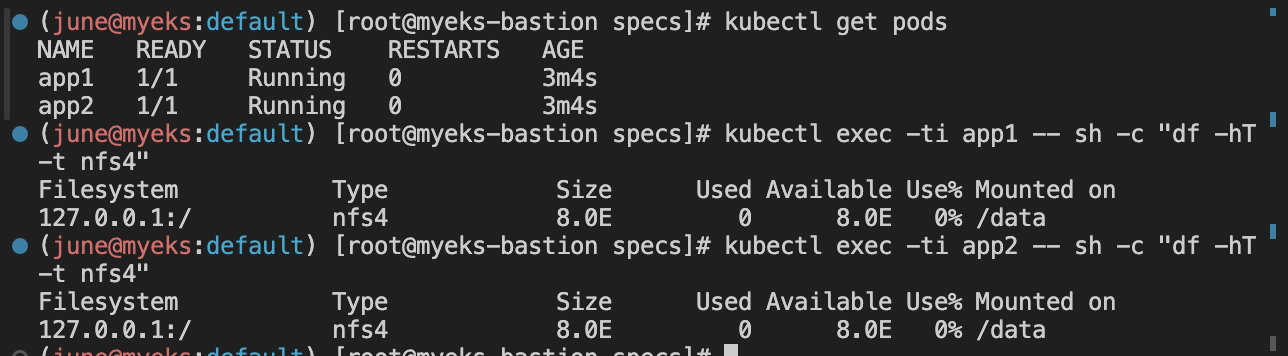
Pod1과 Pod2가 같은 EFS를 공유하는것을 확인할 수 있습니다.
tree /mnt/myefs # 작업용EC2에서 확인
tail -f /mnt/myefs/out1.txt # 작업용EC2에서 확인
kubectl exec -ti app1 -- tail -f /data/out1.txt
kubectl exec -ti app2 -- tail -f /data/out2.txt
이런 마운트 정보를 가지고 있고,
작업용 EC2

pod1

pod2

각각의 환경에서 EFS에서 읽어도 내용이 같이 기록되고 확인할 수 있습니다.
클린업
# 쿠버네티스 리소스 삭제
kubectl delete pod app1 app2
kubectl delete pvc efs-claim && kubectl delete pv efs-pv && kubectl delete sc efs-sc
EKS Persistent Volumes for Instance Store & Add NodeGroup
인스턴스 스토어 구조

데이터 손실이 가능하다.
중요한것보다는 캐시를 사용하는게 좋다.
aws ec2 describe-instance-types \
--filters "Name=instance-type,Values=c5*" "Name=instance-storage-supported,Values=true" \
--query "InstanceTypes[].[InstanceType, InstanceStorageInfo.TotalSizeInGB]" \
--output table
인스턴스 볼륨이 있는 C5타입의 정보를 확인합니다.
eksctl create nodegroup -c $CLUSTER_NAME -r $AWS_DEFAULT_REGION --subnet-ids "$PubSubnet1","$PubSubnet2","$PubSubnet3" --ssh-access \
-n ng2 -t c5d.large -N 1 -m 1 -M 1 --node-volume-size=30 --node-labels disk=nvme --max-pods-per-node 100 --dry-run > myng2.yaml신규 노드 그룹을 생성해줍니다.
cat <<EOT > nvme.yaml
preBootstrapCommands:
- |
# Install Tools
yum install nvme-cli links tree jq tcpdump sysstat -y
# Filesystem & Mount
mkfs -t xfs /dev/nvme1n1
mkdir /data
mount /dev/nvme1n1 /data
# Get disk UUID
uuid=\$(blkid -o value -s UUID mount /dev/nvme1n1 /data)
# Mount the disk during a reboot
echo /dev/nvme1n1 /data xfs defaults,noatime 0 2 >> /etc/fstab
EOTcat <<EOT > nvme.yaml 명령어를 사용하여 nvme.yaml 이라는 파일을 만들었고, 이 파일에는 새로운 EKS 노드에 실행할 초기 명령어들이 들어있습니다. 이 명령어들은 새로 연결된 NVMe 디스크에 파일 시스템을 생성하고, 디스크를 /data 디렉토리에 마운트하며, 부팅 시 자동으로 마운트하도록 /etc/fstab 파일에 추가합니다.
sed -i -n -e '/volumeType/r nvme.yaml' -e '1,$p' myng2.yaml
eksctl create nodegroup -f myng2.yaml
sed -i -n -e '/volumeType/r nvme.yaml' 명령어를 사용해 nvme.yaml 파일의 내용을 다른 설정 파일에 삽입합니다.
eksctl create nodegroup -f myng2.yaml 명령어로 myng2.yaml 설정 파일을 기반으로 새 노드그룹 ng2를 생성합니다.
eksctl 명령어의 로그에서 마지막에 ip-192-168-1-215.ap-northeast-2.compute.internal라는 이름을 가진 노드가 준비되었고, 클러스터 myeks에 새로운 관리형 노드그룹이 성공적으로 생성되었습니다.
노드 보안그룹 ID 확인
NG2SGID=$(aws ec2 describe-security-groups --filters Name=group-name,Values=*ng2* --query "SecurityGroups[*].[GroupId]" --output text)
aws ec2 authorize-security-group-ingress --group-id $NG2SGID --protocol '-1' --cidr 192.168.1.100/32
보안그룹에 추가를 해줍니다.

콘솔에서 확인해보면 인스턴스 타입중에서 c5d.large가 있습니다.
해당 노드의 ip주소를 확인해보면 192.168.1.215입니다.
위의 노드 그룹 생성 명령으로 확인한 로그의 ip주소와 동일합니다.
워커노드 Ssh 접속
N4=<각자 자신의 워커 노드4번 Private IP 지정>
N4=192.168.1.215
ssh ec2-user@$N4 hostname
새로 생성된 노드에 접속할 수 있습니다.
sudo nvme list
sudo lsblk -e 7 -d
sudo df -hT -t xfs
sudo tree /data
ssh ec2-user@$N4 sudo cat /etc/fstab
해당 노드에서 사용 가능한 스토리지에 관한 정보를 제공합니다
sudo nvme list:
- 이 명령은 NVMe 기반 스토리지 디바이스의 리스트를 보여줍니다. 여기서는 두 개의 디바이스가 있습니다:
- /dev/nvme0n1: EBS 볼륨, 32.21 GB 사용 가능.
- /dev/nvme1n1: EC2 인스턴스 스토리지, 50.00 GB 사용 가능.
sudo lsblk -e 7 -d:
- lsblk 명령은 시스템에 연결된 모든 스토리지 블록 디바이스의 정보를 보여줍니다. -e 7 옵션은 루프 디바이스를 숨깁니다. -d 옵션은 하위 디바이스 또는 파티션 정보 없이 주요 디바이스만 표시합니다.
- 결과에서 두 NVMe 디바이스가 보입니다. /dev/nvme1n1는 /data 디렉토리에 마운트되어 있습니다.
sudo df -hT -t xfs:
- df 명령은 파일 시스템의 디스크 공간 사용량을 보여줍니다. -h 옵션은 가독성을 높이기 위해 용량을 휴먼 리더블 포맷으로 표시합니다. -T 옵션은 파일 시스템 타입을 함께 표시합니다. -t xfs는 XFS 파일 시스템 타입을 가진 디바이스만 보여줍니다.
- 출력에서 두 XFS 파일 시스템이 나타납니다. 하나는 루트 파일 시스템(/)에, 다른 하나는 /data에 마운트되어 있습니다.
kubectl describe node -l disk=nvme | grep Allocatable: -A7
max-pod를 확인할 수 있습니다. 100개까지 되네요
라벨을 이 노드 그룹을 만들때 disk=nvme라고 해서 바로 찾을 수 있었습니다.
스토리지 클래스 재생성
기존 삭제
kubectl delete -f local-path-storage.yaml
sed -i 's/opt/data/g' local-path-storage.yaml
kubectl apply -f local-path-storage.yaml
로컬 스토리지 프로비저닝을 위한 설정이 변경되고 적용됩니다.
kubectl delete -f local-path-storage.yaml:
- 이 명령은 local-path-storage.yaml 파일에 정의된 모든 리소스(네임스페이스, 서비스 계정, 역할, 클러스터 역할, 역할 바인딩, 클러스터 역할 바인딩, 배포, 스토리지 클래스, 컨피그맵)를 삭제합니다.
sed -i 's/opt/data/g' local-path-storage.yaml:
- sed 명령은 로컬 스토리지 프로비저너가 데이터를 저장할 기본 디렉토리를 변경하기 위해 사용됩니다.
kubectl apply -f local-path-storage.yaml:
- 수정된 local-path-storage.yaml 파일을 다시 적용하여 삭제된 리소스를 재생성합니다. 이번에는 데이터가 /data 디렉토리에 저장되도록 설정이 변경되었습니다.
로컬 스토리지 프로비저너가 물리적 호스트 머신의 /data 디렉토리를 사용하여 지속적인 볼륨을 프로비저닝하도록 설정이 갱신되었습니다.
노드 그룹
Graviton (ARM) Instance 노드그룹 - Link

g가 들어가는 graviton 시리즈를 활용해서 만들어봅니다.
kubectl get nodes -L kubernetes.io/arch
위 커맨드를 사용해서 현재 사용하는 노드듣의 아키텍쳐를 확인할 수 있습니다. 현재는 amd64입니다.
eksctl create nodegroup -c $CLUSTER_NAME -r $AWS_DEFAULT_REGION --subnet-ids "$PubSubnet1","$PubSubnet2","$PubSubnet3" --ssh-access \
-n ng3 -t t4g.medium -N 1 -m 1 -M 1 --node-volume-size=30 --node-labels family=graviton --dry-run > myng3.yaml
eksctl create nodegroup -f myng3.yaml

현재 배포로 노드그룹 ng3가 생성되었습니다.
kubectl get nodes --label-columns eks.amazonaws.com/nodegroup,kubernetes.io/arch
인스턴스 아키텍쳐 arm64인것을 확인했습니다.
kubectl describe nodes --selector family=graviton
인스턴스 패밀리가 그래비톤인것만 디스크라이브 하도록했는데 해당 노드에 대한 정보 역시 잘 나와줍니다.
Taint 셋팅
aws eks update-nodegroup-config --cluster-name $CLUSTER_NAME --nodegroup-name ng3 --taints "addOrUpdateTaints=[{key=frontend, value=true, effect=NO_EXECUTE}]"
Taint 업데이트를 해줍니다.

그리고 AWS EKS 콘솔에서 ng3 노드그룹에 대해서 업데이트 기록을 확인해보면 기록이 되어있습니다 .
aws eks describe-nodegroup --cluster-name $CLUSTER_NAME --nodegroup-name ng3 | jq .nodegroup.taints
적용된 taint값은 키 밸류로 이렇게 확인 가능합니다.
이 태인트는 frontend=true 라벨이 없는 파드가 해당 노드에서 실행되지 못하도록 합니다.
NO_EXECUTE 효과는 해당 라벨을 가지지 않은 파드가 해당 노드에 이미 실행 중일 경우 없애지는 않지만, 새로운 파드가 그 노드에 스케줄링 되는 것을 방지합니다.
태인트는 파드가 노드에 스케줄링되는 것을 허용하거나 제한하는 방법을 제공합니다.
graviton에서 실행해보기
cat << EOT > busybox.yaml
apiVersion: v1
kind: Pod
metadata:
name: busybox
spec:
terminationGracePeriodSeconds: 3
containers:
- name: busybox
image: busybox
command:
- "/bin/sh"
- "-c"
- "while true; do date >> /home/pod-out.txt; cd /home; sync; sync; sleep 10; done"
tolerations:
- effect: NoExecute
key: frontend
operator: Exists
EOT파드를 만드는 파일을 다음과 같이 설정해줍니다.
kubectl apply -f busybox.yaml
kubectl apply -f busybox.yaml
그리고 바로 배포 해줍니다.
kubectl get pod -owide
해당 파드가 배포되어있는 노드의 아이피를 확인하니 Graviton타입의 인스턴스 맞는것 확인했습니다 .
클린업
kubectl delete pod busybox
eksctl delete nodegroup -c $CLUSTER_NAME -n ng3
스팟 인스턴스를 사용
ec2-instance-selector 설치
curl -Lo ec2-instance-selector https://github.com/aws/amazon-ec2-instance-selector/releases/download/v2.4.1/ec2-instance-selector-`uname | tr '[:upper:]' '[:lower:]'`-amd64 && chmod +x ec2-instance-selector
mv ec2-instance-selector /usr/local/bin/
ec2-instance-selector --version
다음 명령으로 인스턴스 셀렉터를 설치해줍니다.
ec2-instance-selector --vcpus 2 --memory 4 --gpus 0 --current-generation -a x86_64 --deny-list 't.*' --output table-wide
위 명령어의 기준들을 만족하는 (cpu 2 메모리4 x86_64 아키텍쳐) 사용가능한 스팟 인스턴스들의 목록을 보여줍니다.
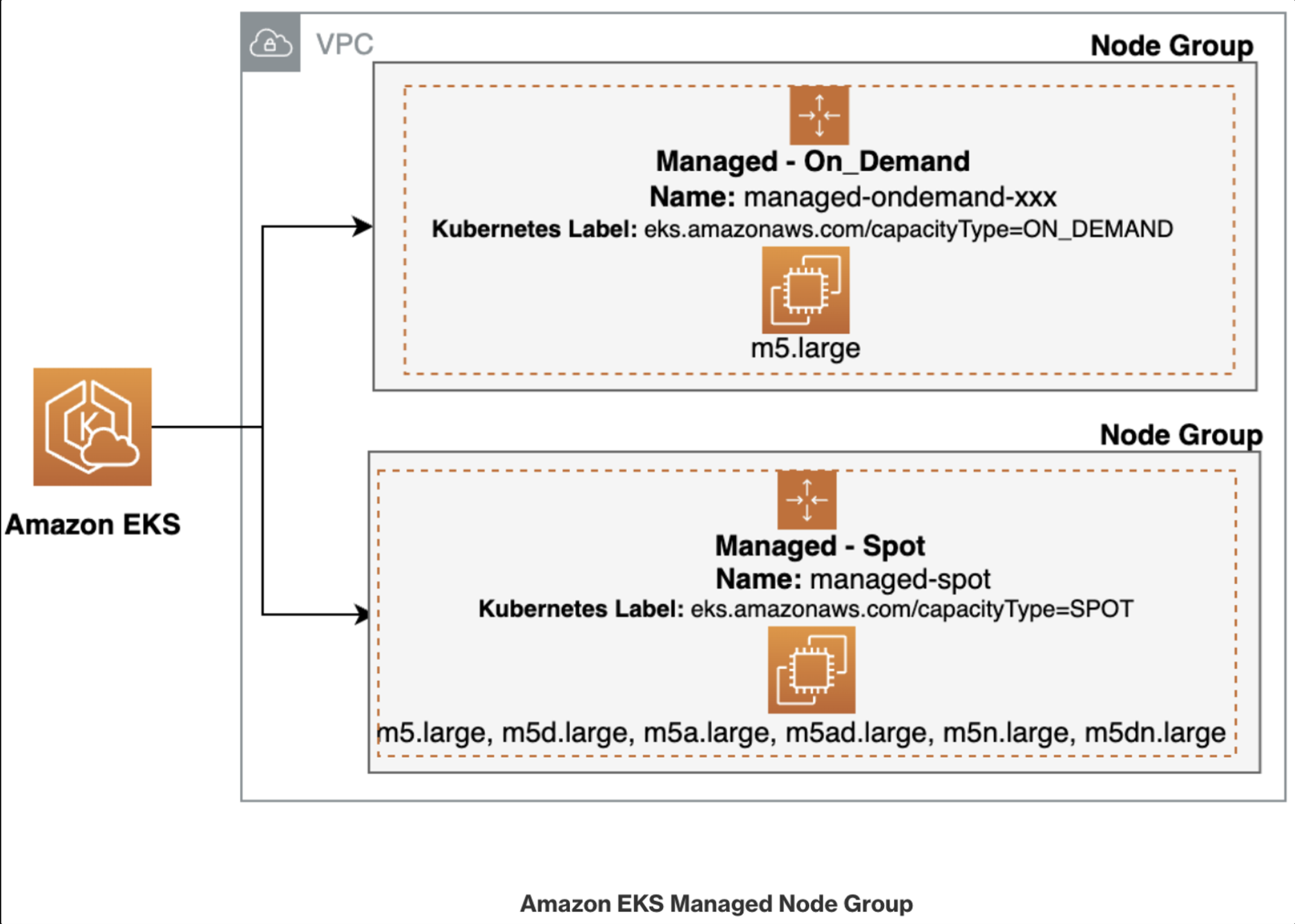
스팟 인스턴스 사용 전략
- 언제든 종료될 수 있기 때문에 dev 와 stg에 스팟을 적용시키고, prd는 온디맨드로 구성하면좋다.
kubectl get nodes -l eks.amazonaws.com/capacityType=ON_DEMAND
kubectl get nodes -L eks.amazonaws.com/capacityType
현재 사용하고 있는 노드들은 전부 on_demend로 사용중입니다.
role AWSServiceRoleForAmazonEKSNodegroup 테스트
aws eks create-nodegroup \
--cluster-name $CLUSTER_NAME \
--nodegroup-name managed-spot \
--subnets $PubSubnet1 $PubSubnet2 $PubSubnet3 \
--node-role arn:aws:iam::018768293104:role/eksctl-myeks-nodegroup-ng1-NodeInstanceRole-q0UU9UjJ0iKU \
--instance-types c5.large c5d.large c5a.large \
--capacity-type SPOT \
--scaling-config minSize=2,maxSize=3,desiredSize=2 \
--disk-size 20
node-role 은 각자 자신의 노드롤 ARN을 입력해야합니다.

이 ARN을 참조하면 됩니다.
aws eks wait nodegroup-active --cluster-name $CLUSTER_NAME --nodegroup-name managed-spot
kubectl get pod -owide
다음 명령을 하고, AWS EKS 콘솔에 가면 managed-spot이라는 새로운 노드그룹을 확인할 수 있습니다.


노드 정보에서 확인하면, 컴퓨팅 두개 확인했고, 해당 타입으로 인스턴스가 두개 생성된것 볼 수 있습니다.
kubectl get nodes -L eks.amazonaws.com/capacityType,eks.amazonaws.com/nodegroup
해당 명령으로 확인한 capacitytype이 spot으로 잘 실행되고 있는 것을 확인할 수 있습니다.
스팟에서 파드 실행
cat << EOT > busybox.yaml
apiVersion: v1
kind: Pod
metadata:
name: busybox
spec:
terminationGracePeriodSeconds: 3
containers:
- name: busybox
image: busybox
command:
- "/bin/sh"
- "-c"
- "while true; do date >> /home/pod-out.txt; cd /home; sync; sync; sleep 10; done"
nodeSelector:
eks.amazonaws.com/capacityType: SPOT
EOTkubectl apply -f busybox.yaml
파드를 만드는 파일을 생성하고 적용합니다.
nodeSelector부분에서 SPOT에서만 생겨라고 지정하고 있습니다.

이 ip는 spot인스턴스의 Ip입니다.

이 ip는 spot인스턴스의 Ip입니다.

실제 kube-ops-view에서 확인했을때에도 해당 spot 인스턴스에서 실행중인것 확인했습니다.
클린업
kubectl delete pod busybox
eksctl delete nodegroup -c $CLUSTER_NAME -n managed-spot
개인적으로 재밌게 할 수 있는 파트였던거 같은데 티스토리 오류로 글이 두번이나 날아가서 더 볼륨있게 딥다이브하며 다시 쓰거나 그럴 수 없었 던 것 같습니 :(. 다른 부분들도 추후에 마음을 추스리고 더 추가할 수 있도록 해보겠습니다.





댓글