about me

20'S LIFE IN SYDNEY and BUSAN

EKS 스터디 CloudNet@팀의 AEWS 2기에 작성된 자료를 베이스로 작성된 블로깅입니다.환경 배포
https://ap-northeast-2.console.aws.amazon.com/cloudformation/home?region=ap-northeast-2#/stacks/create?stackName=myeks&templateURL=https:%2F%2Fs3.ap-northeast-2.amazonaws.com%2Fcloudformation.cloudneta.net%2FK8S%2Feks-oneclick3.yaml
이렇게 yaml파일에 oneclick3인지 확인하세요
특이사항이 있다면 이번에 사용하는 워커노드들은 프로메테우스와 그라파나 등등 사용할 것들이 많으므로 t3.xlarge 스펙을 사용합니다.
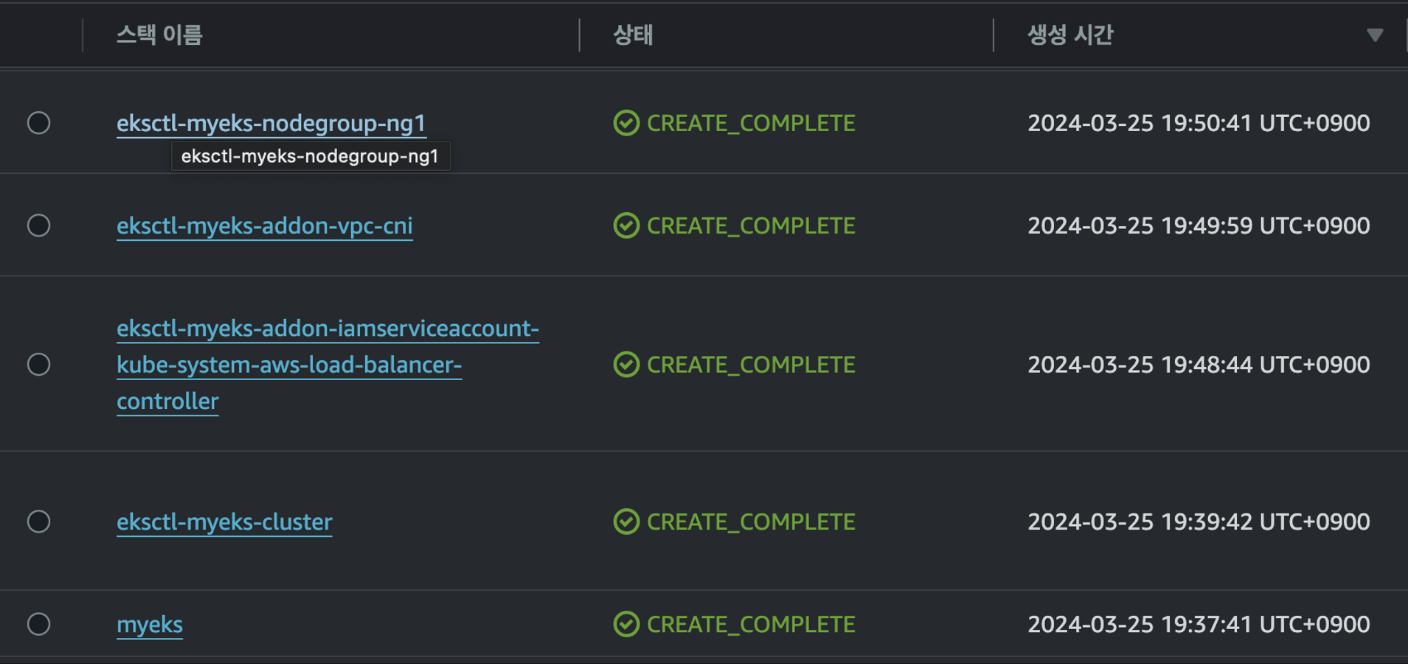
만들어진 스택들은 cloudformation에서 다음과같이 확인이 가능합니다. (1주 2주 쌓일수록 미리 셋팅되는 것들이 많네요)
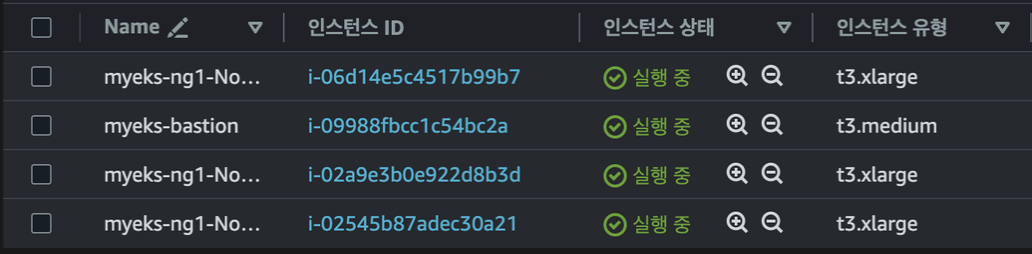
배포가 완료되었으면 이렇게 bastion Host 인스턴스 하나와 node group으로 인해 만들어진 t3.xlarge 클래스 인스턴스들이 세개가 확인 가능합니다.
환경설정
# 노드 IP 확인 및 PrivateIP 변수 지정
N1=$(kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2a -o jsonpath={.items[0].status.addresses[0].address})
N2=$(kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2b -o jsonpath={.items[0].status.addresses[0].address})
N3=$(kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2c -o jsonpath={.items[0].status.addresses[0].address})
echo "export N1=$N1" >> /etc/profile
echo "export N2=$N2" >> /etc/profile
echo "export N3=$N3" >> /etc/profile
echo $N1, $N2, $N3
# 노드 보안그룹 ID 확인
NGSGID=$(aws ec2 describe-security-groups --filters Name=group-name,Values=*ng1* --query "SecurityGroups[*].[GroupId]" --output text)
aws ec2 authorize-security-group-ingress --group-id $NGSGID --protocol '-1' --cidr 192.168.1.100/32
# 워커 노드 SSH 접속
for node in $N1 $N2 $N3; do ssh ec2-user@$node hostname; done이젠 너무 익숙하네요
bastion host 인스턴스에 ssh접속을 해서 다음의 커멘드로 환경 셋팅을 해줍니다.
AWS LB/ExternalDNS/EBS, kube-ops-view 설치
# ExternalDNS
MyDomain=crowsnest.click
echo "export MyDomain=crowsnest.click" >> /etc/profile
MyDomain=gasida.link
echo "export MyDomain=gasida.link" >> /etc/profile
MyDnzHostedZoneId=$(aws route53 list-hosted-zones-by-name --dns-name "${MyDomain}." --query "HostedZones[0].Id" --output text)
echo $MyDomain, $MyDnzHostedZoneId
curl -s -O https://raw.githubusercontent.com/gasida/PKOS/main/aews/externaldns.yaml
MyDomain=$MyDomain MyDnzHostedZoneId=$MyDnzHostedZoneId envsubst < externaldns.yaml | kubectl apply -f -
# kube-ops-view
helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 --set env.TZ="Asia/Seoul" --namespace kube-system
kubectl patch svc -n kube-system kube-ops-view -p '{"spec":{"type":"LoadBalancer"}}'
kubectl annotate service kube-ops-view -n kube-system "external-dns.alpha.kubernetes.io/hostname=kubeopsview.$MyDomain"
echo -e "Kube Ops View URL = http://kubeopsview.$MyDomain:8080/#scale=1.5"
# AWS LB Controller
helm repo add eks https://aws.github.io/eks-charts
helm repo update
helm install aws-load-balancer-controller eks/aws-load-balancer-controller -n kube-system --set clusterName=$CLUSTER_NAME \
--set serviceAccount.create=false --set serviceAccount.name=aws-load-balancer-controller
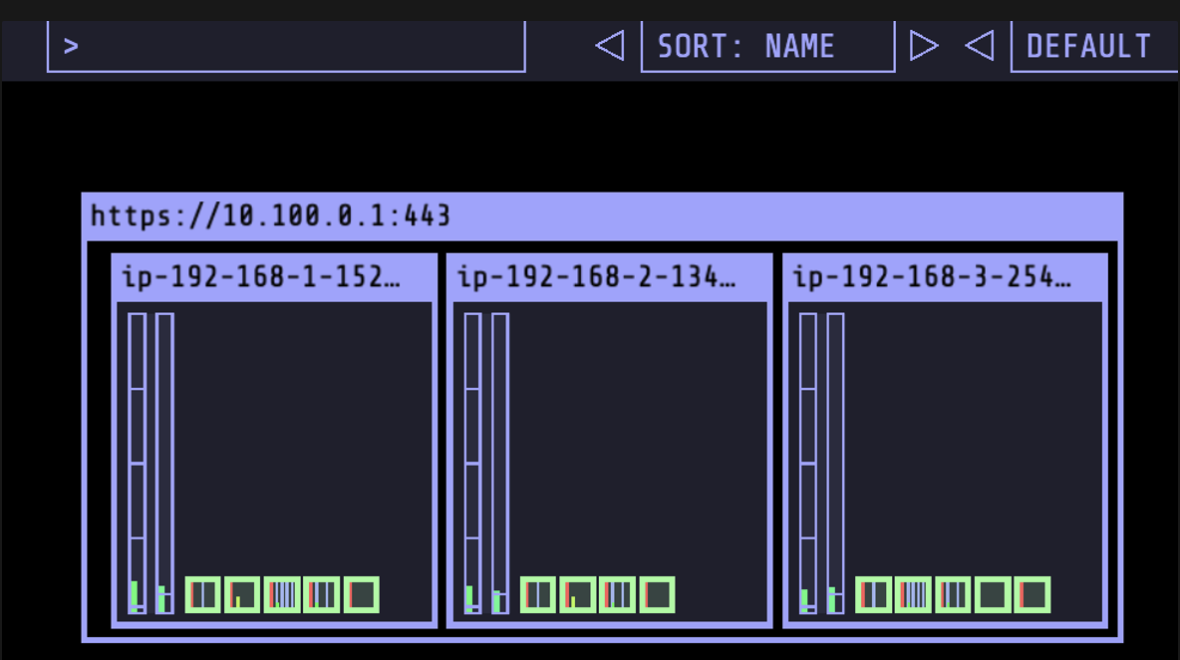
kubeops view가 호스팅되어서 접속 가능한것을 확인하실 수 있습니다.
# EBS csi driver 설치 확인
eksctl get addon --cluster ${CLUSTER_NAME}
kubectl get pod -n kube-system -l 'app in (ebs-csi-controller,ebs-csi-node)'
kubectl get csinodes
# gp3 스토리지 클래스 생성
kubectl get sc
kubectl apply -f https://raw.githubusercontent.com/gasida/PKOS/main/aews/gp3-sc.yaml
kubectl get sc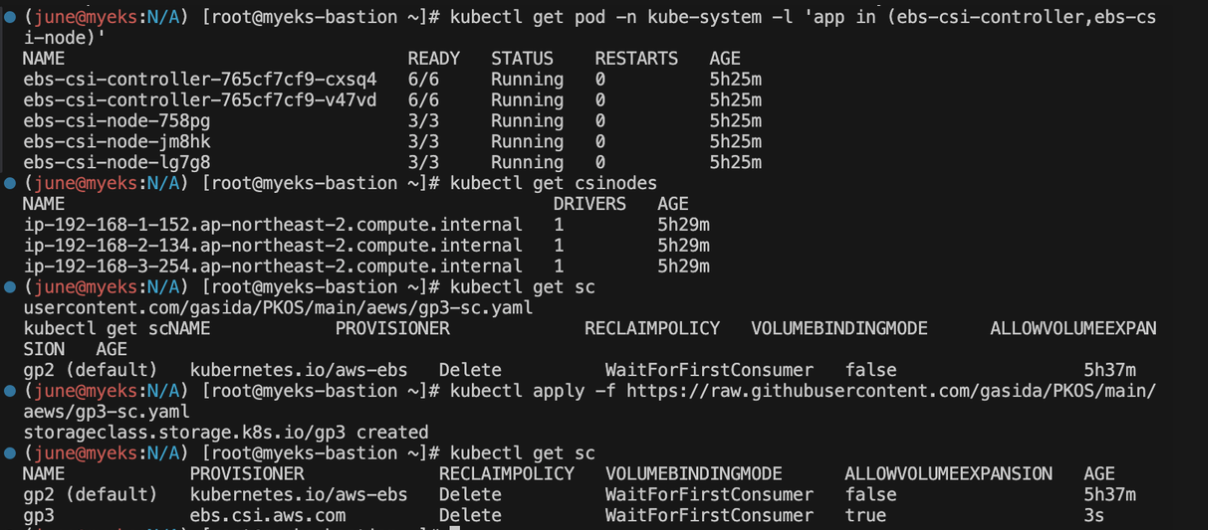
EBS csi driver 와 gp3 스토리지 클래스도 생성해줍니다.
EKS Console
kubectl get ClusterRole | grep eks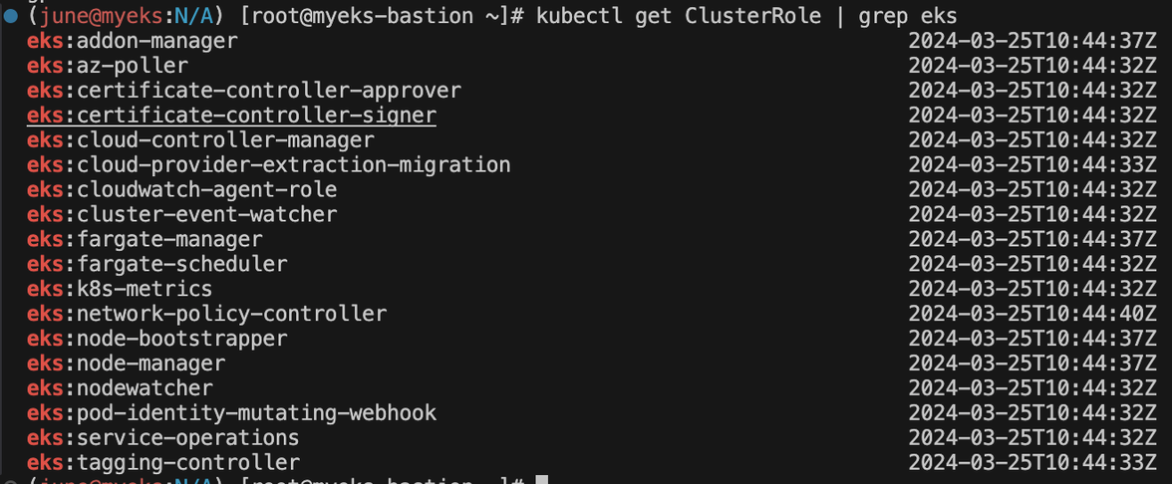
Logging in EKS
https://malwareanalysis.tistory.com/600
악분님의 블로그를 참고합니다.
EKS로깅에는 컨트롤 플레인 로깅과 노드로깅 그리고 애플리케이션 로깅이 있습니다.
EKS 컨트롤 플레인 로그란?
컨트롤 플레인에서 발생한 이벤트를 EKS 옵션을 설정하여 로그로 남길 수 있습니다.
디폴트로는 로깅이 비활성화 되어 있고, 수집된 컨트롤 플레인 로그는 cloudwatch에서 볼 수 있습니다.
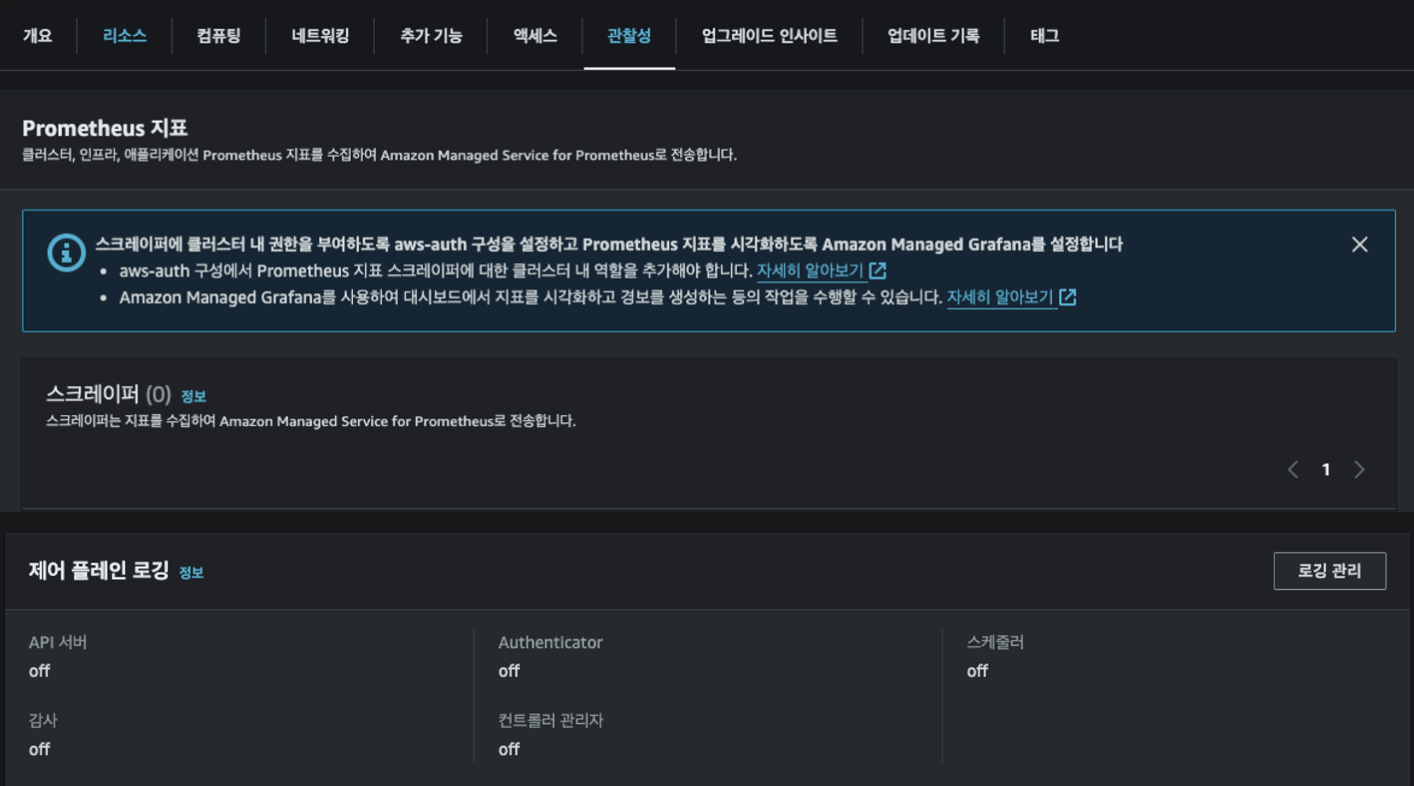
EKS 클러스터에 접속하고, 관찰성에 들어간 뒤, 제어 플레인 로깅을 확인하시면 모두 Off되어있는것을 확인하실 수 있습니다. → default로 비활성화가 된 것 확인한 것입니다.
그리고 컨트롤 플레인에서는 저 다섯개의 항목에 대한 로깅을 활성화 가능하다는 말이 됩니다.
컨트롤 플레인 로깅 정보에 대한 설명은 다음과 같습니다.
API 서버
클러스터에 대한 API 요청과 관련된 로그입니다.
감사(Audit)
Kubernetes API를 통한 클러스터 액세스와 관련된 로그입니다.
Authenticator
클러스터에 대한 인증 요청과 관련된 로그입니다.
컨트롤러 관리자
클러스터 컨트롤러 상태와 관련된 로그입니다.
스케줄러
예약 결정과 관련된 로그입니다.
eksctl을 사용하여 컨트롤 플레인 로그 활성화 하기
로깅 설정은 CloudWatch필드로 설정합니다.
aws eks update-cluster-config --region $AWS_DEFAULT_REGION --name $CLUSTER_NAME \
--logging '{"clusterLogging":[{"types":["api","audit","authenticator","controllerManager","scheduler"],"enabled":true}]}'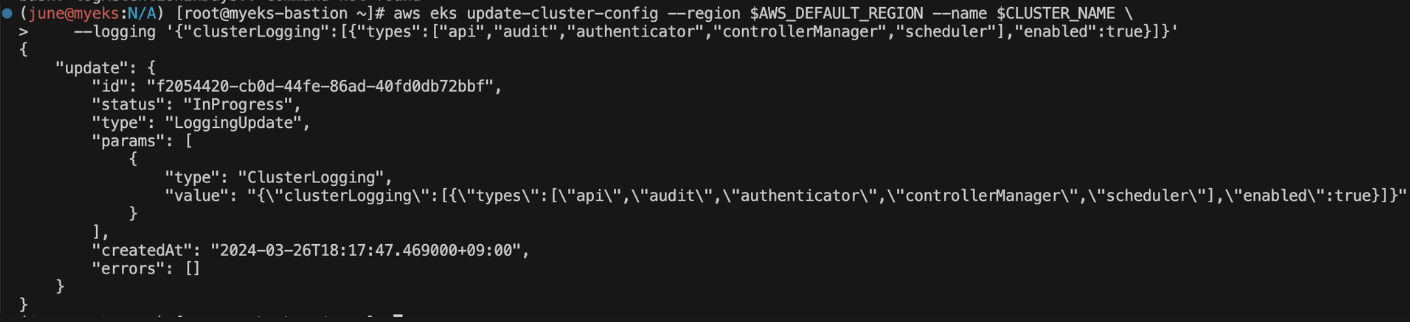
이렇게 터미널에 명령을 하고 나서 다시 AWS 콘솔에서 클러스터에 대한 로깅 정보를 새로고침해줍니다.

그러면 이렇게 모두 활성화 되어있는 것을 확인하실 수 있습니다.
로그 그룹 확인
# 로그 그룹 확인
aws logs describe-log-groups | jq
# 로그 tail 확인 : aws logs tail help
aws logs tail /aws/eks/$CLUSTER_NAME/cluster | more
# 신규 로그를 바로 출력
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --follow
# 필터 패턴
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --filter-pattern <필터 패턴>
# 로그 스트림이름
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix <로그 스트림 prefix> --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-controller-manager --follow
kubectl scale deployment -n kube-system coredns --replicas=1
kubectl scale deployment -n kube-system coredns --replicas=2
# 시간 지정: 1초(s) 1분(m) 1시간(h) 하루(d) 한주(w)
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --since 1h30m
# 짧게 출력
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --since 1h30m --format short
로그 그룹은 다음 커멘드로 확인이 가능합니다.
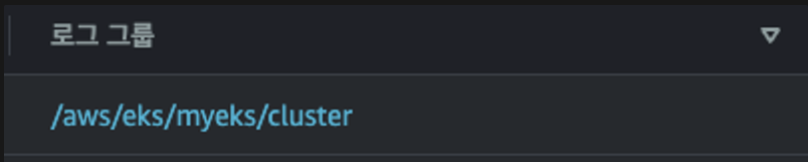
AWS 콘솔상에서는 클라우드 와치의 로그 그룹에서 /aws/eks/myeks/cluster 라는 이름으로 확인이 가능합니다.
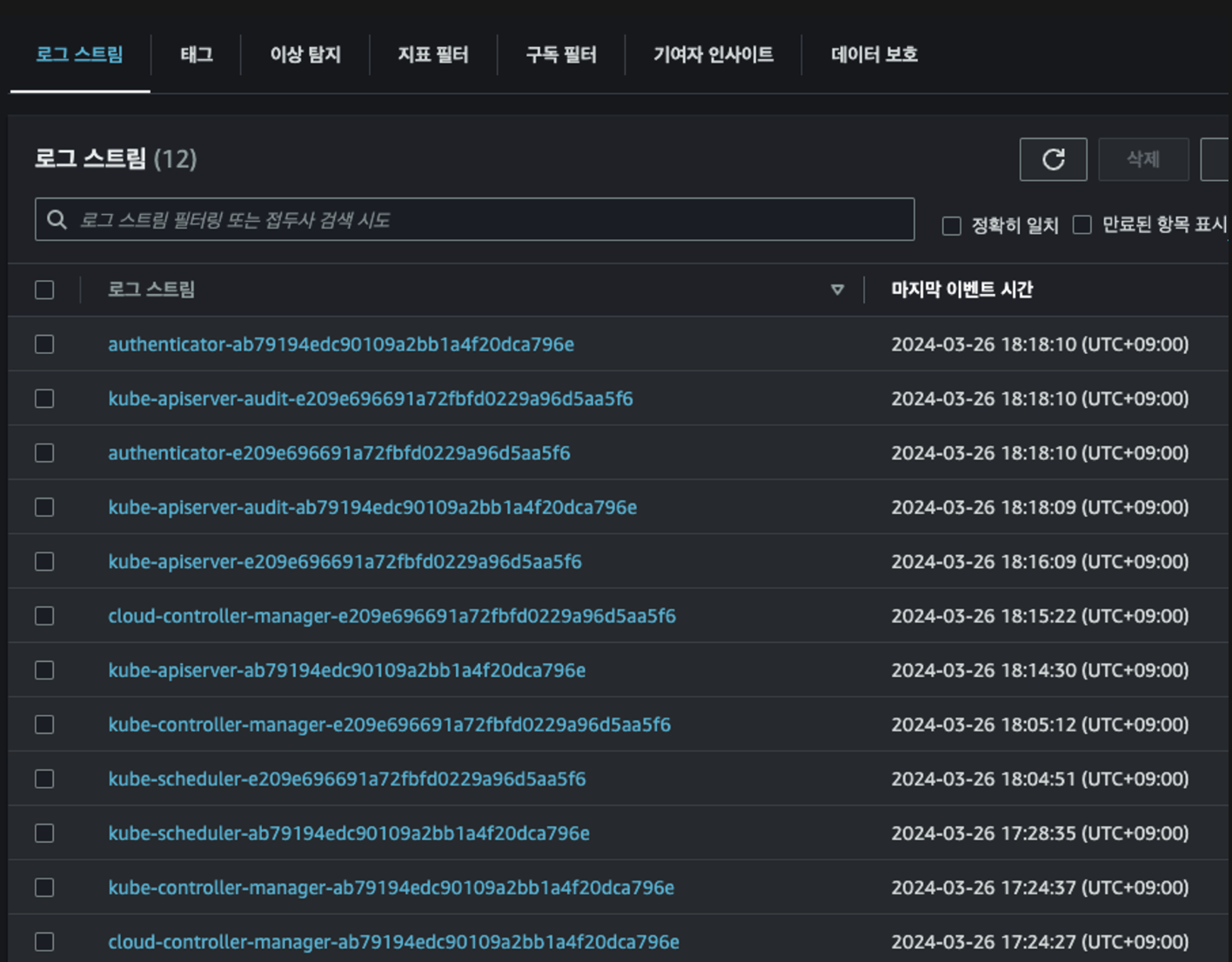
들어가서 로그 스트림을 확인해보면, 아까 컨트롤플레인 로깅에서 활성화 했던 항목들에 대해서 로깅이 되는것을 확인하실 수 있습니다.
클라우드 와치의 Logs Insights를 사용해서 검색을 할 수 있습니다.

위에서 확인한 로그 그룹을 선택해주고 쿼리를 실행하면 됩니다.
# EC2 Instance가 NodeNotReady 상태인 로그 검색
fields @timestamp, @message
| filter @message like /NodeNotReady/
| sort @timestamp desc
# kube-apiserver-audit 로그에서 userAgent 정렬해서 아래 4개 필드 정보 검색
fields userAgent, requestURI, @timestamp, @message
| filter @logStream ~= "kube-apiserver-audit"
| stats count(userAgent) as count by userAgent
| sort count desc
#
fields @timestamp, @message
| filter @logStream ~= "kube-scheduler"
| sort @timestamp desc
#
fields @timestamp, @message
| filter @logStream ~= "authenticator"
| sort @timestamp desc
#
fields @timestamp, @message
| filter @logStream ~= "kube-controller-manager"
| sort @timestamp desc위의 쿼리들을 참고해 커스텀으로 쿼리를 구성하시면 됩니다.
# EKS Control Plane 로깅(CloudWatch Logs) 비활성화
eksctl utils update-cluster-logging --cluster $CLUSTER_NAME --region $AWS_DEFAULT_REGION --disable-types all --approve
# 로그 그룹 삭제
aws logs delete-log-group --log-group-name /aws/eks/$CLUSTER_NAME/cluster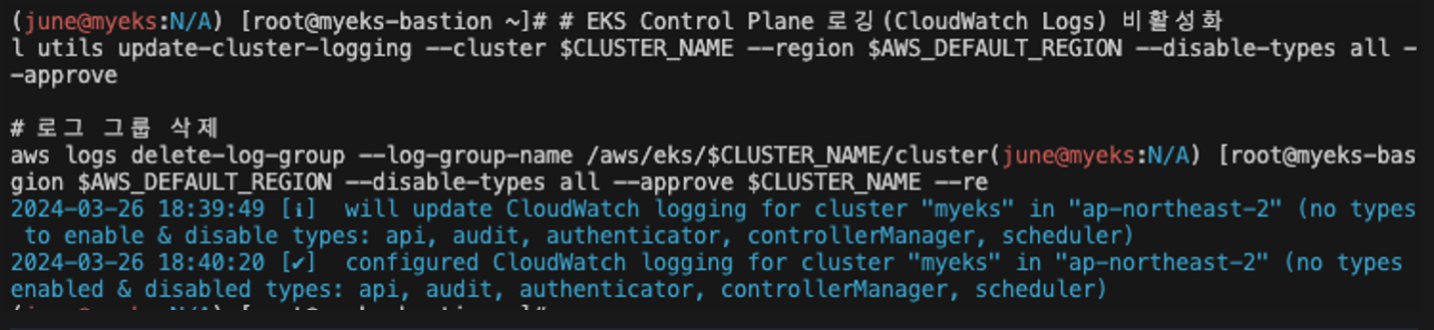
다음 명령으로 로깅을 비활성화 하고 로그 그룹을 삭제할 수 있습니다.
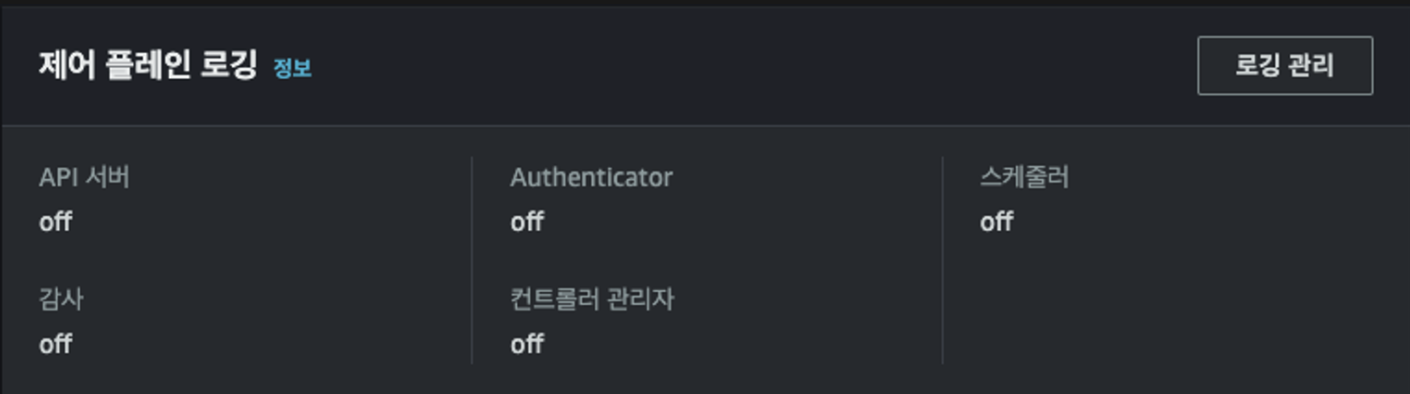
콘솔에서도 off 확인했습니다.
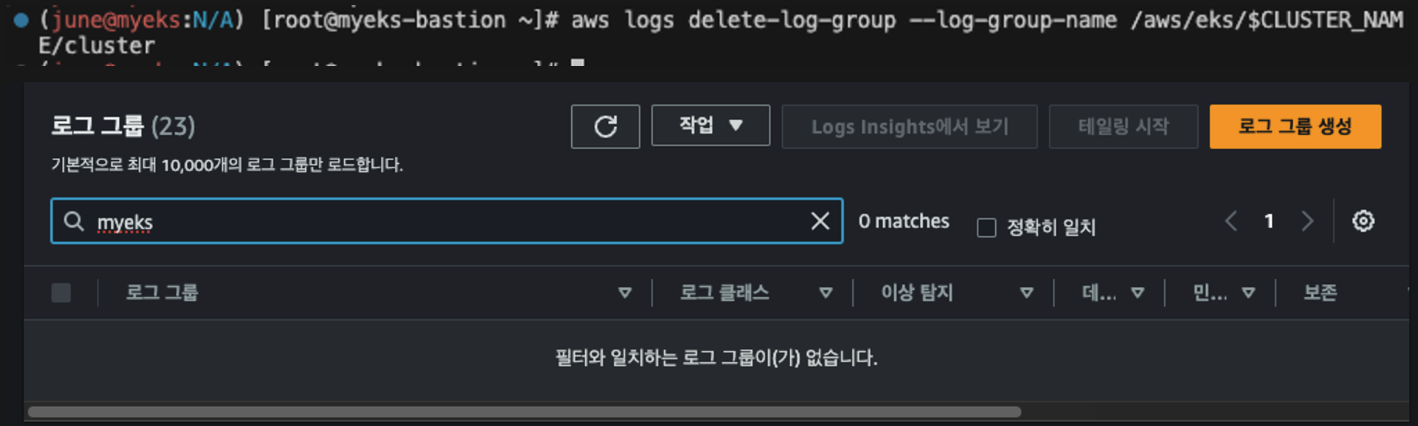
로그 그룹에서도 myeks로 조회되는 로그 그룹 없습니다.
Container(Pod) Logging
Nginx 웹서버 배포
helm을 사용합니다. (여기서부터는 tipy.ee가 아닌 crowsnest.click 도메인을 사용하여 진행합니다.)
helm repo add bitnami https://charts.bitnami.com/bitnami
# 사용 리전의 인증서 ARN 확인
CERT_ARN=$(aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text)
echo $CERT_ARN
# 도메인 확인
echo $MyDomain
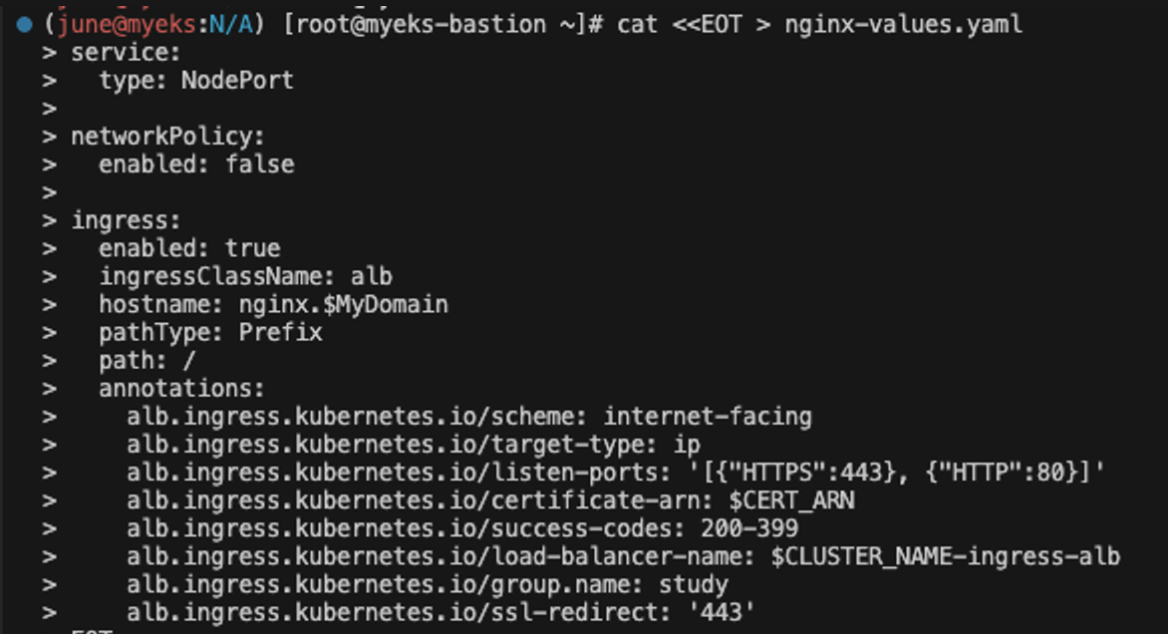
# 파라미터 파일 생성 : 인증서 ARN 지정하지 않아도 가능! 혹시 https 리스너 설정 안 될 경우 인증서 설정 추가(주석 제거)해서 배포 할 것
cat <<EOT > nginx-values.yaml
service:
type: NodePort
networkPolicy:
enabled: false
ingress:
enabled: true
ingressClassName: alb
hostname: nginx.$MyDomain
pathType: Prefix
path: /
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: $CLUSTER_NAME-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
EOT
cat nginx-values.yaml | yh
annotation에 certificate부분 활성화 햇음
파일 내용의 의미는 다음과 같습니다:
- service: Nginx 서비스의 유형을 NodePort로 설정합니다. 이는 외부에서 내부 포트로 접근 가능하게 하는 방식입니다.
- networkPolicy: 네트워크 정책을 사용하지 않도록 설정합니다.
- ingress: 인그레스 리소스를 활성화하고, 여기에 대한 설정을 정의합니다.
- ingressClassName: 사용할 인그레스 클래스 이름을 **alb**로 설정합니다.
- hostname: 인그레스에 접근할 때 사용할 호스트 이름을 **nginx.$MyDomain**으로 설정합니다. 여기서 **$MyDomain**은 사용자의 도메인 이름으로 대체되어야 합니다.
- pathType: 인그레스 경로의 유형을 Prefix로 설정합니다.
- path: 인그레스 경로를 **/**로 설정합니다.
- annotations: 인그레스에 대한 다양한 설정을 주석으로 추가합니다. 예를 들어, ALB(Application Load Balancer)가 인터넷에 노출되도록 설정하고, 타겟 유형을 IP로 설정하며, 리스닝 포트를 HTTP와 HTTPS로 설정합니다.
EKS 환경에서 ALB를 사용하여 Nginx 서비스를 배포하고, HTTPS 리디렉션을 설정하며, 특정 로드 밸런서 이름과 그룹을 지정하는 데 사용됩니다.
배포
helm install nginx bitnami/nginx --version 15.14.0 -f nginx-values.yaml
확인
kubectl get ingress,deploy,svc,ep nginx
kubectl get targetgroupbindings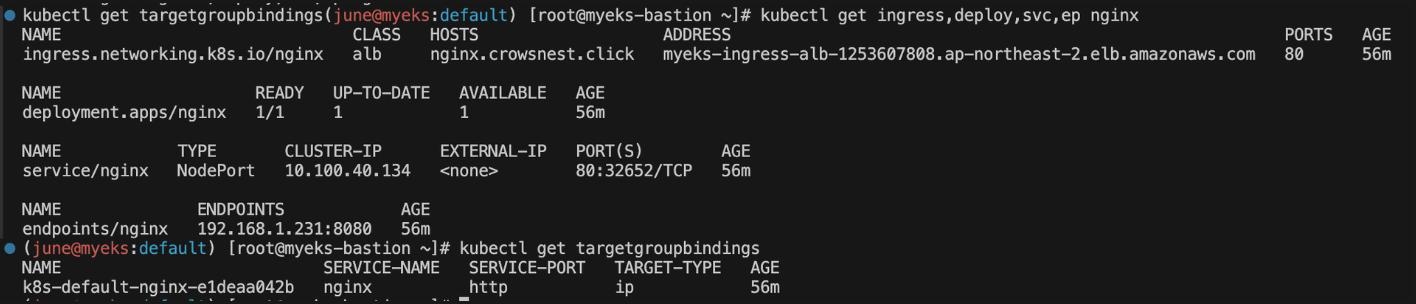
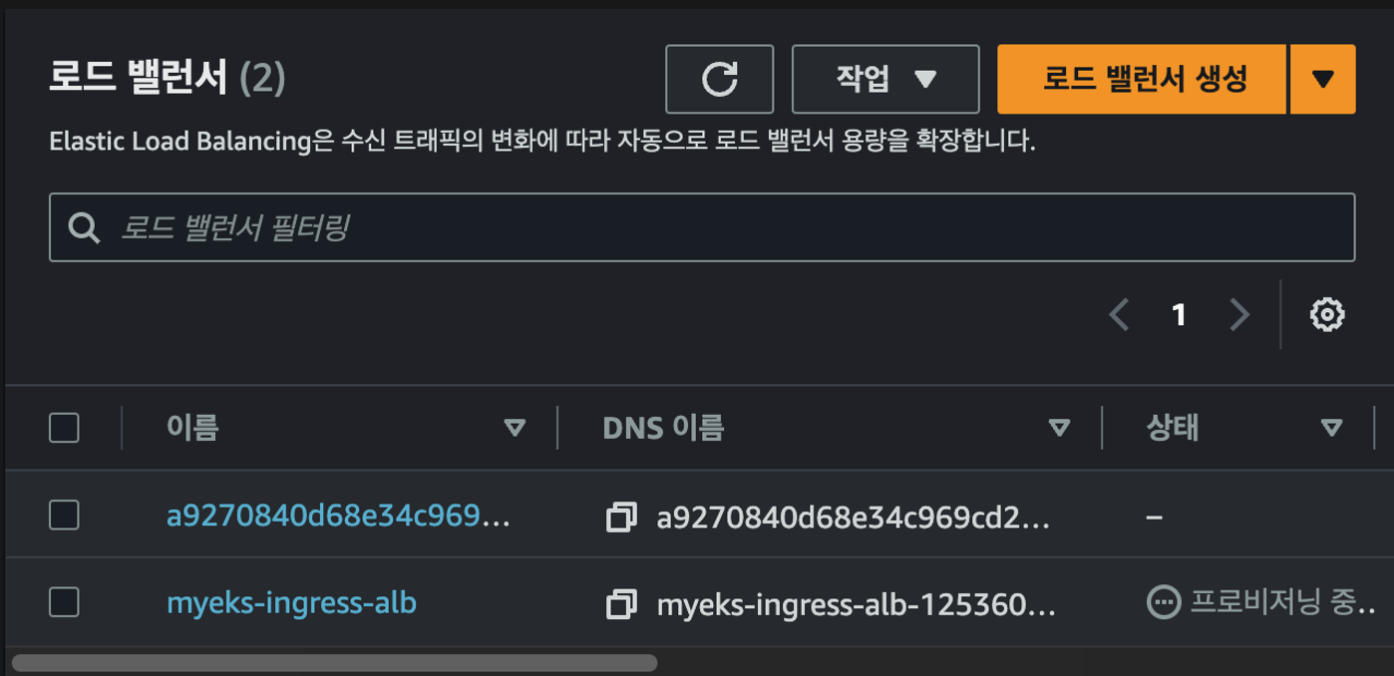
AWS 콘솔상에서는 myeks-ingress-alb로 ingress에서 만든대로 alb가 하나 생성됩니다.
AWS 콘솔상에서는 myeks-ingress-alb로 ingress에서 만든대로 alb가 하나 생성됩니다.
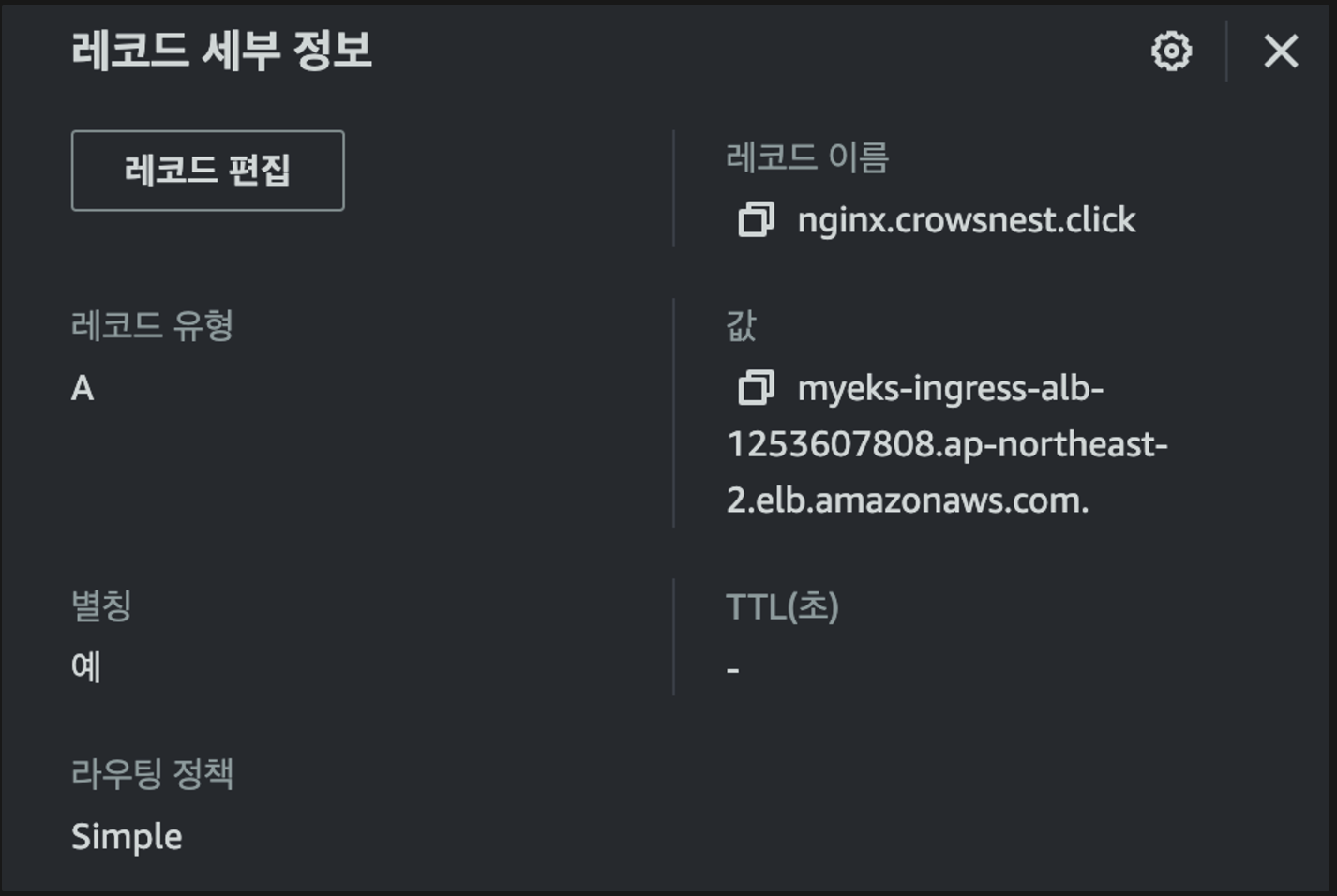
route53에서도 A레코드로 nginx.crowsnest.click이 생겼고, 이건 alb와 매핑되어있습니다.
접속 주소 확인 및 접속 합니다.
echo -e "Nginx WebServer URL = https://nginx.$MyDomain"
curl -s https://nginx.$MyDomain
kubectl logs deploy/nginx -f
# 반복 접속
while true; do curl -s https://nginx.$MyDomain -I | head -n 1; date; sleep 1; done
# (참고) 삭제 시
helm uninstall nginx
물론 도메인으로도 접속 가능합니다.
컨테이너 로그 환경의 로그는 표준 출력 stdout과 표준 에러 stderr로 보내는 것을 권고합니다. - 링크
해당 권고에 따라 작성된 컨테이너 애플리케이션의 로그는 해당 파드 안으로 접속하지 않아도 사용자는 외부에서 kubectl logs 명령어로 애플리케이션 종류에 상관없이,애플리케이션마다 로그 파일 위치에 상관없이, 단일 명령어로 조회 가능합니다.
kubectl logs deploy/nginx -f
nginx 파드의 로그를 확인해보면 제가 브라우저로 접근을 시도했던 기록이랑, elb 헬스체크를 한다고 루트경로를 찌르는것들이 쭉 나오는 것을 확인 가능합니다.
kubectl exec -it deploy/nginx -- ls -l /opt/bitnami/nginx/logs/
Nginx의 로그 파일이 /dev/stdout과 /dev/stderr로 리디렉션되어 있다는 것을 보여줍니다.
- access.log -> /dev/stdout: Nginx의 접근 로그가 표준 출력으로 리디렉션됩니다. 이를 통해 HTTP 요청 로그를 볼 수 있습니다.
- error.log -> /dev/stderr: Nginx의 에러 로그가 표준 에러로 리디렉션됩니다. 이는 오류 메시지와 경고 등을 포함합니다.
nginx docker image 를 확인해봐도 그 권장사항을 따라서 로그를 처리하는것을 확인할 수 있습니다.

Container Insights metrics in Amazon CloudWatch & Fluent Bit (Logs)
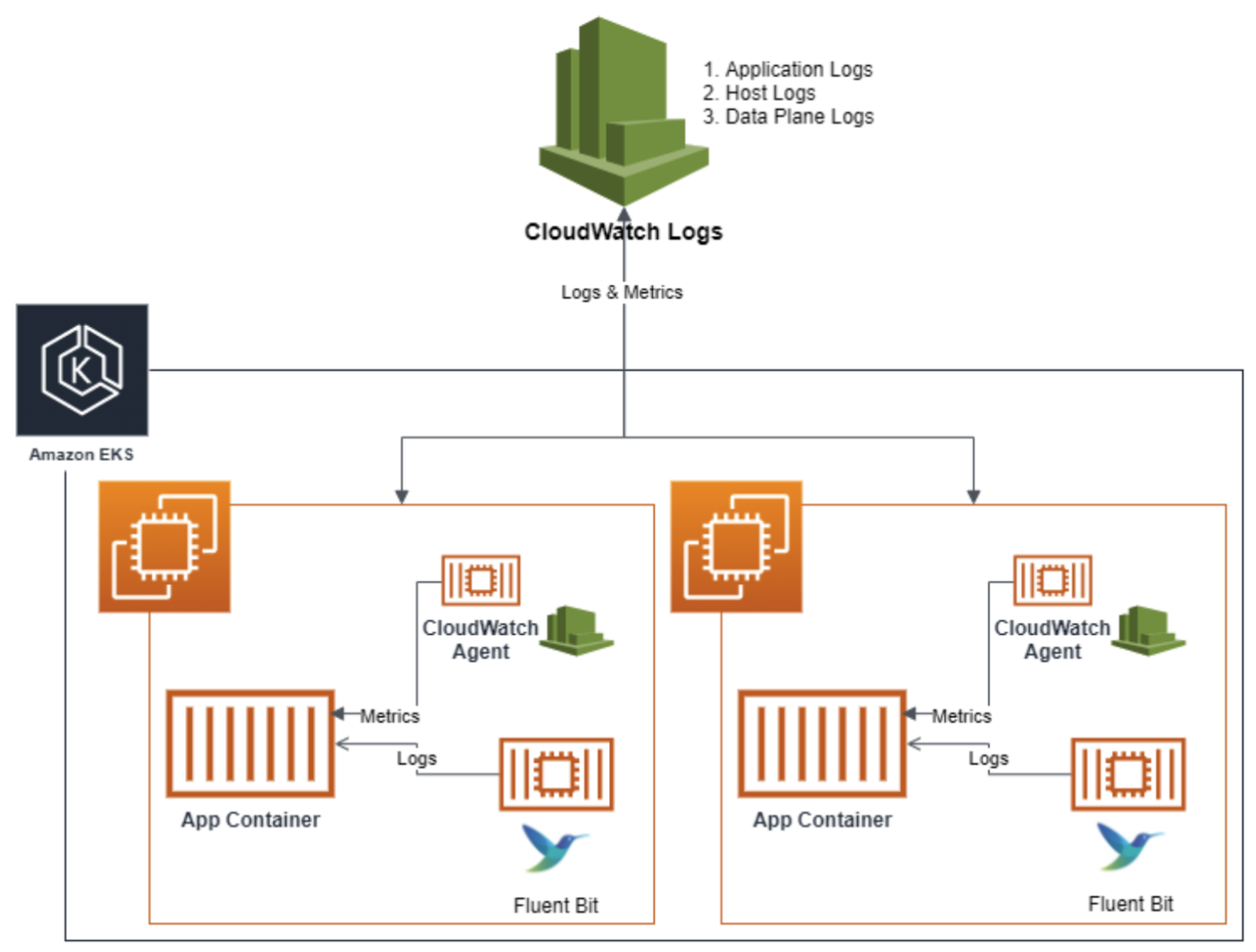
CloudWatch Container Insight (CCI)
Amazon CloudWatch Container Insights는 Amazon EKS와 통합되어 컨테이너화된 애플리케이션 및 마이크로서비스의 모니터링, 트러블슈팅 및 알람을 위한 완전 관리형 관측 서비스입니다.
이 서비스는 컨테이너 자체와 컨테이너가 실행되고 있는 컴퓨팅 인프라에 대한 성능 지표와 로그를 수집하고 시각화합니다.
CloudWatch Container Insights를 사용하면 클러스터에서 발생하는 문제를 빠르게 발견하고 해결할 수 있습니다.
Fluent Bit와 CloudWatch Agent는 다음과 같은 역할을 수행합니다
출처: Fluent Bit Integration in CloudWatch Container Insights for EKS
Fluent Bit
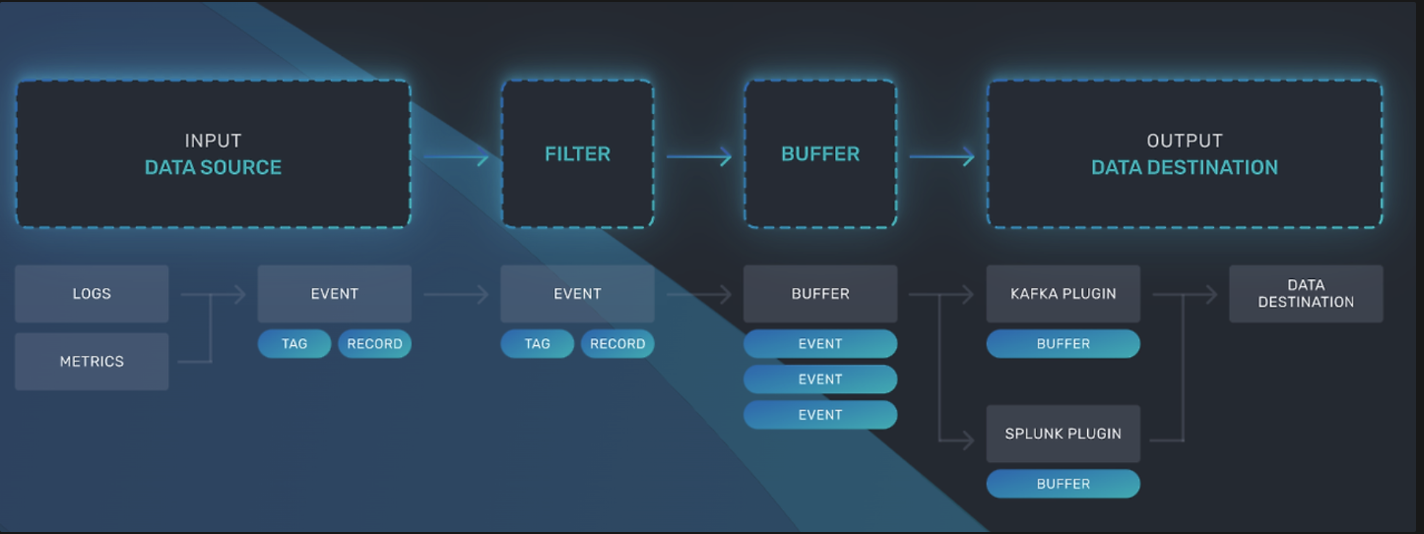
Fluent Bit는 오픈 소스, 다중 플랫폼 로그 프로세서 이며 서로 다른 소스에서 데이터/로그를 수집하고 통합하여 여러 대상으로 보내 는 데 사용됩니다. Fluent Bit는 가볍고 메모리 사용량이 적도록 설계되어 Kubernetes, Docker 등과 같은 컨테이너화된 환경에서 애플리케이션을 포함하거나 함께 배포하는 데 적합합니다.
- 데몬셋으로 실행되어, 모든 노드에서 로그를 수집합니다.
- CloudWatch Logs에 로그를 전송하는 경량 로그 프로세서 및 포워더입니다.
세 가지 주요 종류의 로그를 수집합니다
- 컨테이너/파드 로그:
- 이는 컨테이너에서 생성되는 로그로, /var/log/containers/ 경로에서 수집됩니다.
- 이 로그들은 애플리케이션의 표준 출력(stdout)과 표준 에러(stderr) 스트림을 통해 생성됩니다.
- 노드(호스트) 로그:
- 이는 노드 수준에서 발생하는 시스템 로그로, 일반적인 리눅스 시스템 로그와 유사합니다.
- /var/log/dmesg, /var/log/secure, /var/log/messages 등의 경로에서 수집되며, 시스템 보안, 커널 메시지 등에 대한 정보를 포함할 수 있습니다.
- 쿠버네티스 데이터 플레인 로그:
- 쿠버네티스 클러스터의 데이터 플레인 운영과 관련된 로그로, 특히 쿠버네티스 시스템 컴포넌트의 로그를 말합니다.
- /var/log/journal 경로에서 kubelet, kubeproxy, docker 등의 서비스 로그를 수집합니다. 이러한 로그는 쿠버네티스 클러스터의 작동 상태와 성능 문제를 진단하는 데 중요한 정보를 제공합니다.
CloudWatch Agent
- 메트릭을 수집하여 CloudWatch에 전송합니다.
- 메트릭은 클러스터의 CPU, 메모리, 디스크, 네트워크 사용량 등의 인프라 정보를 포함합니다.
작동 방식
- 클러스터 수준에서 CloudWatch Agent 및 Fluent Bit이 각 노드에 배치됩니다.
- 이 에이전트들은 메트릭과 로그를 수집하고 CloudWatch에 전송합니다.
- CloudWatch에서는 이 데이터를 사용하여 자동화된 대시보드를 제공하며, 이를 통해 성능 지표를 실시간으로 모니터링할 수 있습니다.
- 로그 데이터는 CloudWatch Logs Insights를 통해 분석될 수 있으며, 사용자가 쿼리를 생성하여 로그 데이터를 더 깊이 있게 분석할 수 있습니다.
장점
- 통합된 시각화: CloudWatch를 사용하면 로그 데이터와 메트릭스를 하나의 위치에서 관리하고 시각화할 수 있습니다.
- 성능 모니터링: 애플리케이션 및 인프라의 성능 문제를 실시간으로 모니터링하고 적시에 대응할 수 있습니다.
- 향상된 트러블슈팅: 문제 발생 시 로그 데이터를 기반으로 문제를 신속하게 진단하고 해결할 수 있습니다.
- 비용 효율적: 저장된 로그의 보존 기간을 설정하여 비용을 최적화할 수 있습니다.
- 확장성: 클러스터가 확장됨에 따라 자동으로 로그와 메트릭스 수집이 확장됩니다.
노드의 로그 확인
application 로그 소스(All log files in /var/log/containers → 심볼릭 링크 /var/log/pods/<컨테이너>, 각 컨테이너/파드 로그
ssh ec2-user@$N1 sudo tree /var/log/containers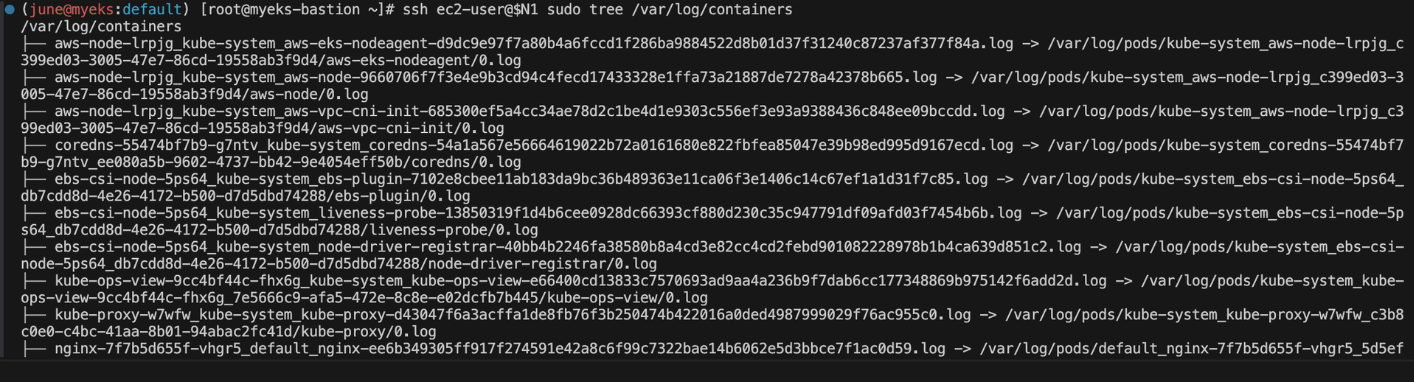
kubectl get ClusterRole | grep eks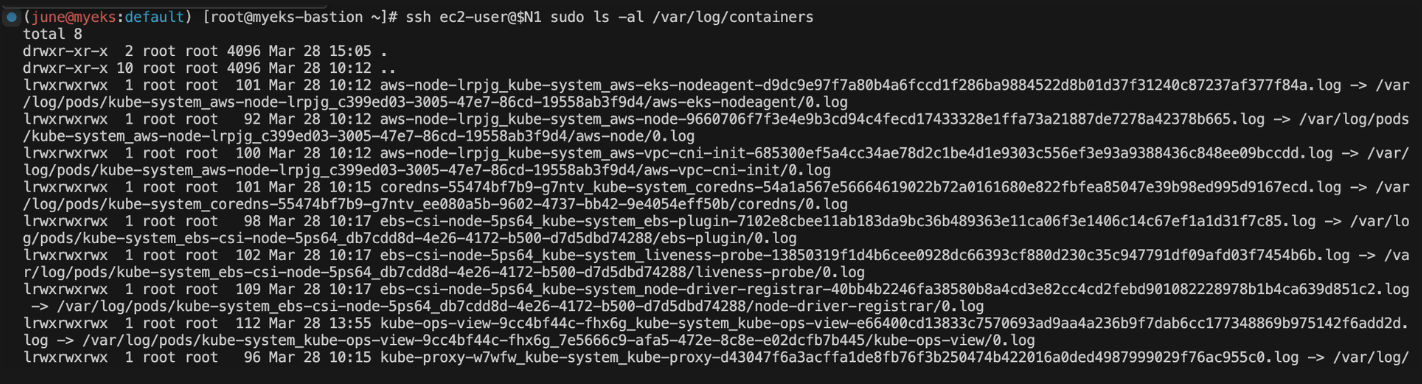
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo tree /var/log/containers; echo; done
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo ls -al /var/log/containers; echo; done세 개의 노드(N1, N2, N3)에서 각각의 /var/log/containers 디렉토리에 있는 파일들을 나열합니다.
이 파일들은 쿠버네티스 클러스터에서 실행 중인 각 컨테이너의 로그를 가리키는 심볼릭 링크입니다.
예를 들어, nginx-7f7b5d655f-vhgr5_default_nginx-ee6b349305ff917f274591e42a8c6f99c7322bae14b6062e5d3bbce7f1ac0d59.log는 실제로 /var/log/pods/default_nginx-7f7b5d655f-vhgr5_5d5ef7fa-1764-47f8-8c87-f14a58b14618/nginx/0.log 경로의 로그 파일을 가리키고 있습니다.
이 로그 파일들은 주로 kubectl logs 명령으로 액세스되지만, Fluent Bit와 같은 로그 수집기를 사용하여 Amazon CloudWatch와 같은 로깅 백엔드로 전송되기도 합니다.
nginx 배포의 컨테이너 내에서 /opt/bitnami/nginx/logs/ 디렉토리의 내용을 나열하려고 시도하면, 결과적으로 access.log와 error.log가 각각 표준 출력(/dev/stdout)과 표준 에러(/dev/stderr)로 리다이렉트되고 있음을 확인할 수 있습니다.
host 로그 소스(Logs from/var/log/dmesg, /var/log/secure, and /var/log/messages), 노드(호스트) 로그
로그 위치 확인
ssh ec2-user@$N1 sudo tree /var/log/ -L 1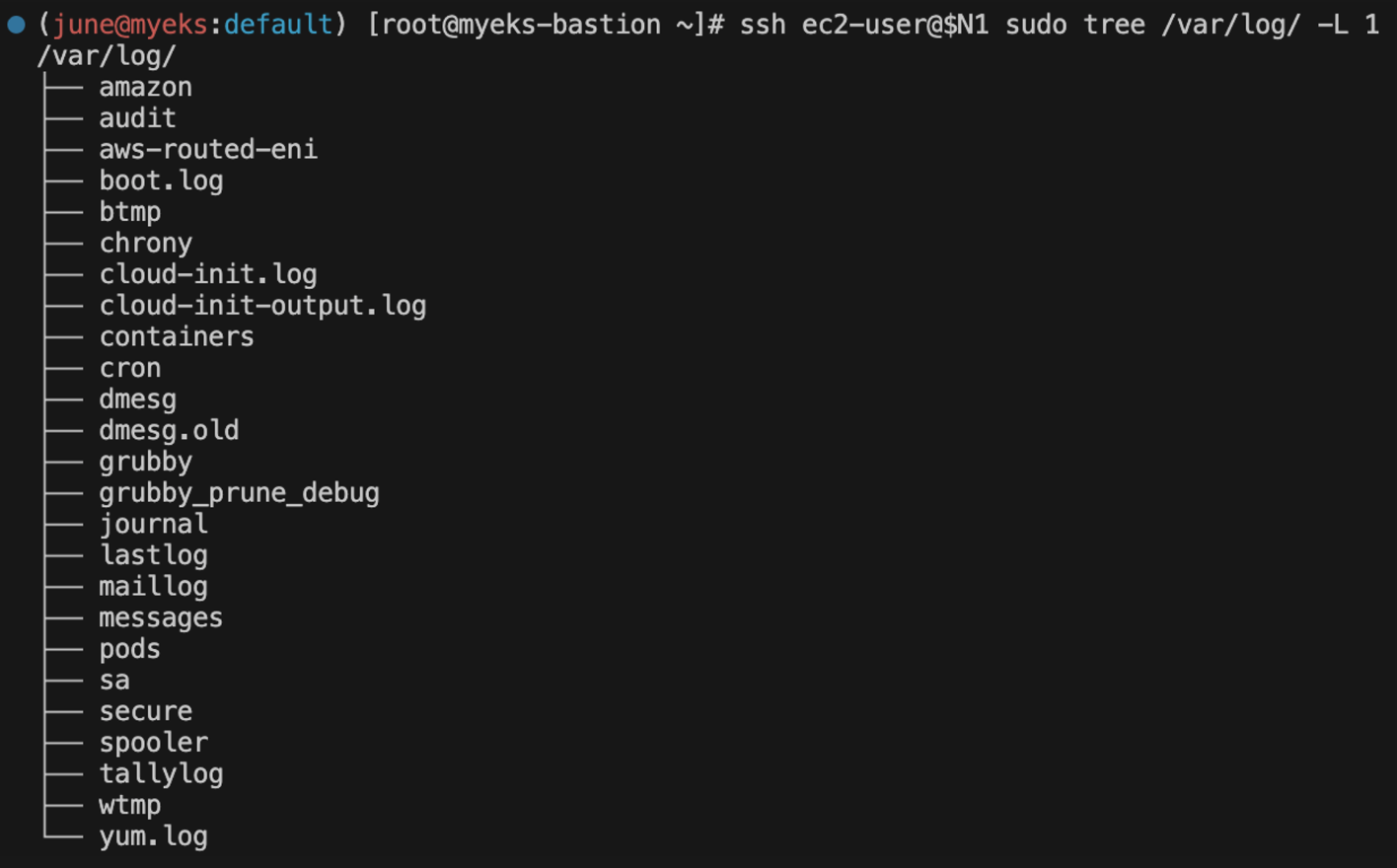
원격 노드(N1)의 /var/log/ 디렉토리 내의 항목을 한 레벨까지 나열합니다. 그 결과, 일반적인 리눅스 시스템 로그 디렉토리와 파일들이 표시됩니다.
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo tree /var/log/ -L 1; echo; done
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo ls -la /var/log/; echo; done위의 명령어들은 각각 클러스터의 노드들에 있는 /var/log/ 디렉토리의 내용을 나열합니다.
tree /var/log/ -L 1 명령은 /var/log/ 디렉토리와 그 바로 아래 있는 하위 항목들을 표시합니다. 이것은 시스템 로그 구조의 개요를 제공합니다.
ls -la /var/log/ 명령은 /var/log/ 디렉토리 내의 모든 파일과 디렉토리에 대한 상세 리스트를 보여줍니다.
여기서 중요한 몇 가지 디렉토리 및 파일들의 용도는 다음과 같습니다:
- /var/log/audit/: 보안 관련 로그를 포함하며, 시스템에서 수행된 모든 보안 관련 이벤트를 추적합니다.
- /var/log/cloud-init.log: 클라우드 인스턴스 초기화 중 발생한 로그를 포함합니다. 클라우드 환경에서 인스턴스 시작 시 수행되는 스크립트와 관련된 로그들입니다.
- /var/log/containers/: 쿠버네티스 컨테이너 로그가 저장되는 곳입니다. 이는 컨테이너의 표준 출력과 에러 스트림을 포함합니다.
- /var/log/messages: 일반 시스템 메시지 로그를 포함하며, 시스템 관련 중요 로그를 보관합니다.
- /var/log/secure: 인증 및 권한 부여와 관련된 로그를 포함합니다.
호스트 로그 확인
ssh ec2-user@$N1 sudo tail /var/log/dmesg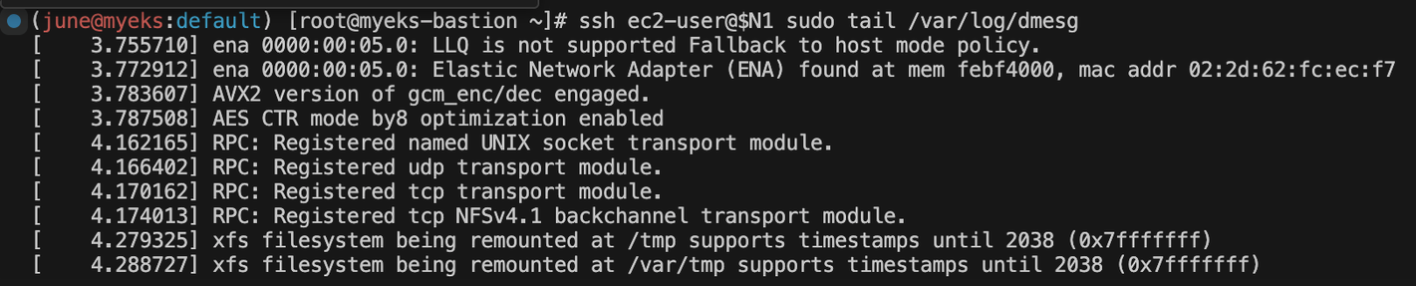
이 경우, 여기에 나와 있는 메시지는 Elastic Network Adapter (ENA) 및 보안 설정과 관련된 메시지입니다.
tail /var/log/dmesg은 가장 최근에 기록된 시스템 메시지 로그를 표시합니다. dmesg 로그는 시스템 부팅 중 하드웨어 및 드라이버에 관련된 메시지를 담고 있습니다.
ssh ec2-user@$N1 sudo tail /var/log/secure
tail /var/log/secure 명령어는 /var/log/secure 파일의 마지막 부분을 표시합니다. 이 로그는 시스템에 대한 인증 시도와 관련된 정보를 포함합니다.
ssh ec2-user@$N1 sudo tail /var/log/messages
tail /var/log/messages 명령어는 일반 시스템 이벤트 로그를 보여줍니다. 이 파일에는 다양한 시스템 관련 메시지가 포함되어 있으며, 부팅, 시스템 에러, 크론 작업 실행 등에 대한 정보가 포함될 수 있습니다.
로그에는 systemd에 의한 사용자 세션 생성 및 삭제에 대한 정보가 나타납니다.
for log in dmesg secure messages; do echo ">>>>> Node1: /var/log/$log <<<<<"; ssh ec2-user@$N1 sudo tail /var/log/$log; echo; done
for log in dmesg secure messages; do echo ">>>>> Node2: /var/log/$log <<<<<"; ssh ec2-user@$N2 sudo tail /var/log/$log; echo; done
for log in dmesg secure messages; do echo ">>>>> Node3: /var/log/$log <<<<<"; ssh ec2-user@$N3 sudo tail /var/log/$log; echo; done모든 노드들에 대해서 표시합니다.
dataplane 로그 소스(/var/log/journal for kubelet.service, kubeproxy.service, and docker.service), 쿠버네티스 데이터플레인 로그
로그 위치 확인
ssh ec2-user@$N1 sudo tree /var/log/journal -L 1
ssh ec2-user@$N1 sudo ls -la /var/log/journal
/var/log/journal 디렉토리의 내용을 보여줍니다.
journal 디렉토리는 시스템 로깅 데몬인 systemd-journald가 관리하는 시스템 이벤트 로그들을 저장하는 곳입니다.
tree 명령어와 ls -la 명령어 둘 다 이 디렉토리 내부를 나열하고 있는데, 두 개의 서브 디렉토리가 보이고, 이 서브 디렉토리들은 특정한 시스템 실행에 관련된 로그 데이터를 담고 있으며, 각기 다른 시스템 부트나 서비스에 대한 로그 정보를 포함할 수 있습니다.
systemd-journald가 수집한 로그 데이터는 시스템의 상세한 작동 상태를 파악하거나 문제 해결을 위한 중요한 정보를 제공할 수 있습니다.
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo tree /var/log/journal -L 1; echo; done
# 저널 로그 확인 - 링크
ssh ec2-user@$N3 sudo journalctl -x -n 200
ssh ec2-user@$N3 sudo journalctl -fCloudWatch Container observability 설치 - Link cloudwatch-agent & fluent-bit - 링크 & Setting up Fluent Bit - Docs
# 설치
aws eks create-addon --cluster-name $CLUSTER_NAME --addon-name amazon-cloudwatch-observability
aws eks list-addons --cluster-name myeks --output table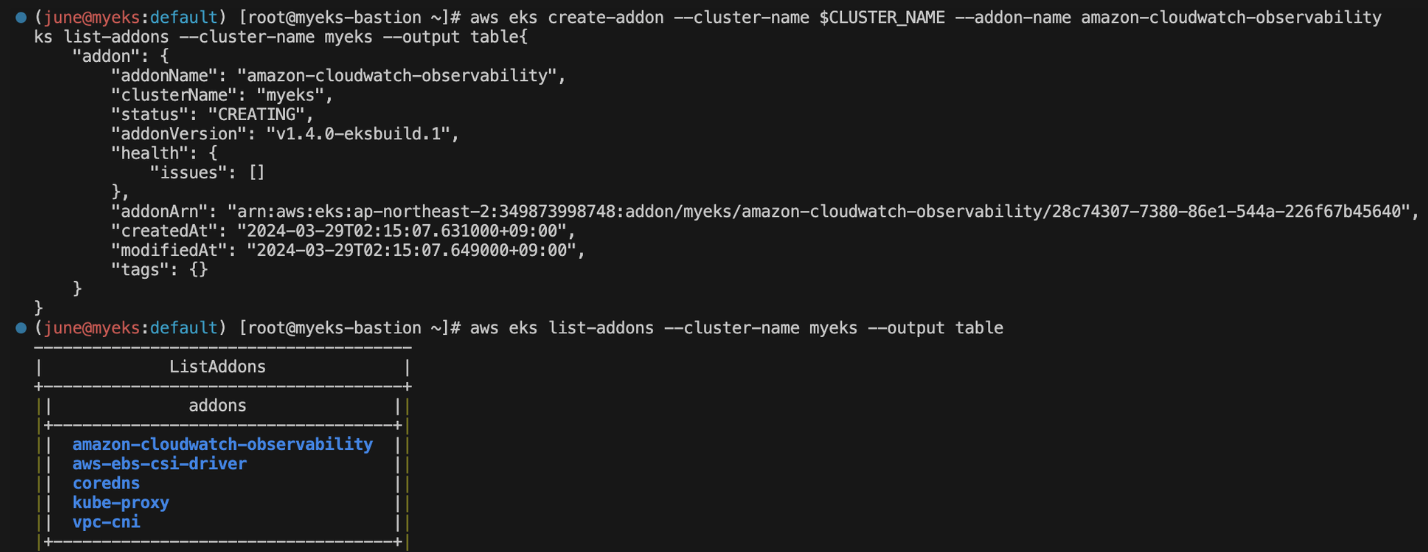
# 설치 확인
kubectl get-all -n amazon-cloudwatch
kubectl get ds,pod,cm,sa,amazoncloudwatchagent -n amazon-cloudwatch
kubectl describe clusterrole cloudwatch-agent-role amazon-cloudwatch-observability-manager-role # 클러스터롤 확인
kubectl describe clusterrolebindings cloudwatch-agent-role-binding amazon-cloudwatch-observability-manager-rolebinding # 클러스터롤 바인딩 확인
kubectl -n amazon-cloudwatch logs -l app.kubernetes.io/component=amazon-cloudwatch-agent -f # 파드 로그 확인
kubectl -n amazon-cloudwatch logs -l k8s-app=fluent-bit -f # 파드 로그 확인
# cloudwatch-agent 설정 확인
kubectl describe cm cloudwatch-agent-agent -n amazon-cloudwatch
#Fluent bit 파드 수집하는 방법 : Volumes에 HostPath를 살펴보자! >> / 호스트 패스 공유??? 보안상 안전한가? 좀 더 범위를 좁힐수는 없을까요?
kubectl describe -n amazon-cloudwatch ds cloudwatch-agent#Fluent bit 파드 수집하는 방법 : Volumes에 HostPath를 살펴보자! >> / 호스트 패스 공유??? 보안상 안전한가? 좀 더 범위를 좁힐수는 없을까요?
kubectl describe -n amazon-cloudwatch ds cloudwatch-agent
# Fluent Bit 로그 INPUT/FILTER/OUTPUT 설정 확인 - 링크
## 설정 부분 구성 : application-log.conf , dataplane-log.conf , fluent-bit.conf , host-log.conf , parsers.conf
kubectl describe cm fluent-bit-config -n amazon-cloudwatch
# Fluent Bit 파드가 수집하는 방법 : Volumes에 HostPath를 살펴보자!
kubectl describe -n amazon-cloudwatch ds fluent-bit
aws eks delete-addon --cluster-name $CLUSTER_NAME --addon-name amazon-cloudwatch-observabilityAWS EKS 클러스터에 Amazon CloudWatch 관측 기능을 추가하는 명령을 실행했습니다. 이 기능은 클러스터의 모니터링과 로깅을 강화해주며, amazon-cloudwatch-observability라는 이름으로 생성되었습니다.
클러스터에 설치된 애드온 목록을 조회했고, amazon-cloudwatch-observability가 정상적으로 리스트에 포함된 것을 확인했습니다.
CloudWatch 에이전트와 관련된 설정, 권한(role), 권한 바인딩(rolebinding), 그리고 로그를 확인하기 위한 다양한 kubectl 명령어를 사용했습니다. 이는 클러스터에서 로깅과 모니터링이 잘 이루어지고 있는지를 파악하기 위함입니다.
특히, kubectl describe 명령을 통해 CloudWatch 에이전트와 Fluent Bit의 설정 및 실행 상태를 자세히 확인했습니다. 이들은 Kubernetes 클러스터의 로그를 수집하고 Amazon CloudWatch로 전송하는 역할을 합니다.
마지막으로, EKS 클러스터의 노드 중 하나에서 /dev/disk 디렉토리를 확인해, EBS 볼륨 및 기타 스토리지 장치의 식별 정보를 보여주었습니다.
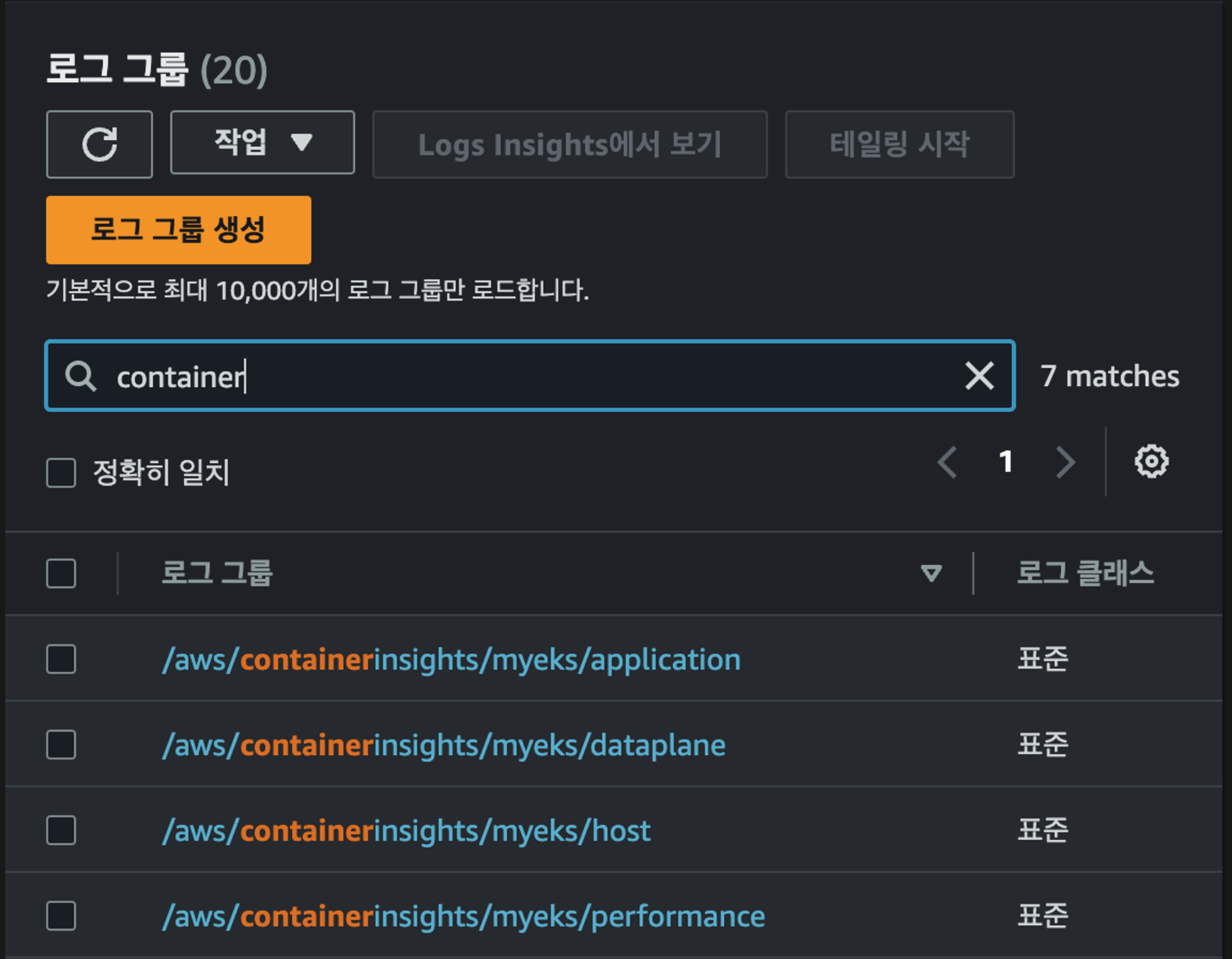
로깅 확인: CloudWatch 로그 그룹
# 부하 발생
curl -s https://nginx.$MyDomain
yum install -y httpd
ab -c 500 -n 30000 https://nginx.$MyDomain/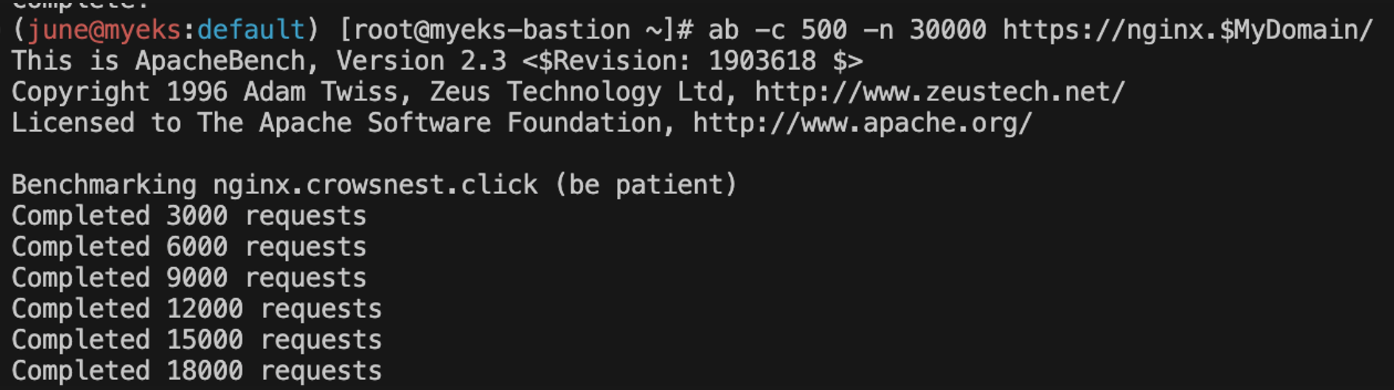
# 파드 직접 로그 모니터링
kubectl logs deploy/nginx -f
해당 로그 그룹 application 경로에서 nginx 로그를 확인 가능합니다.
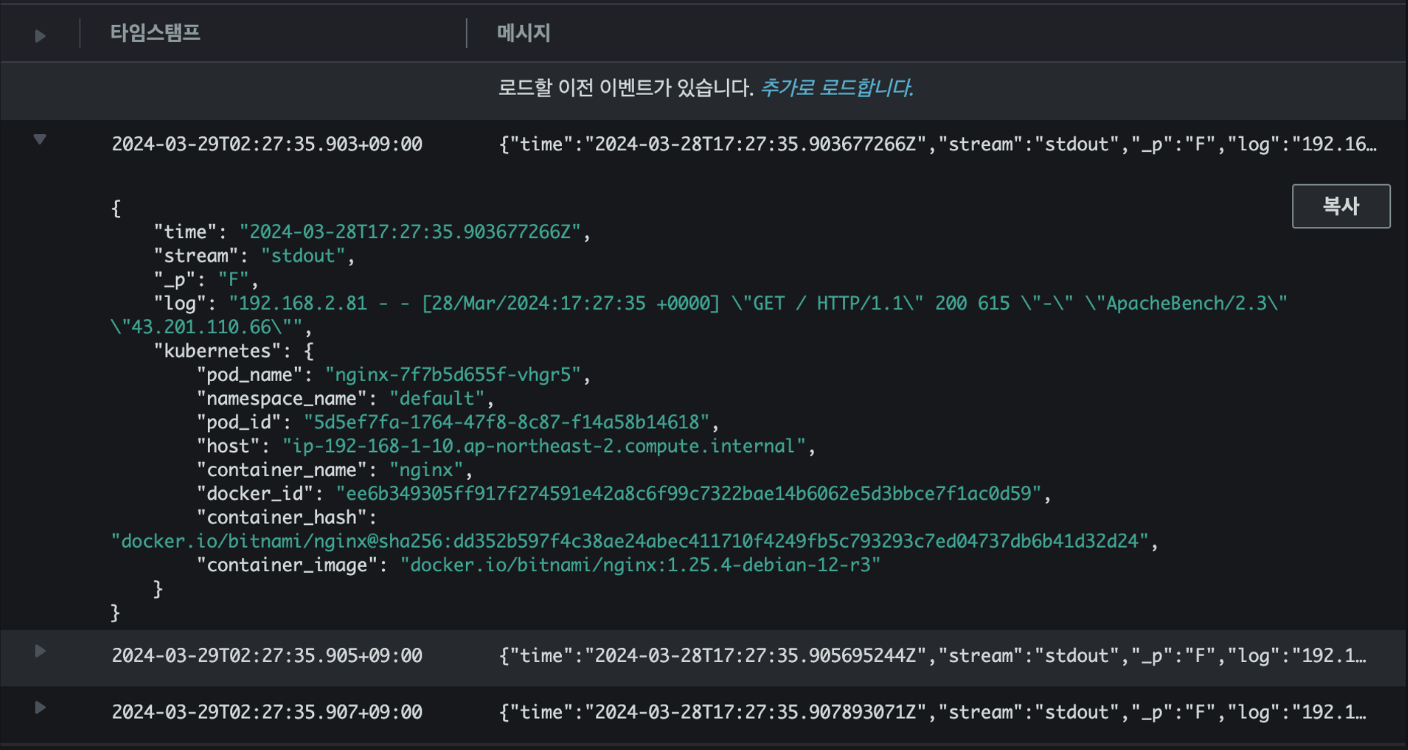
Logs Insights
# Application log errors by container name : 컨테이너 이름별 애플리케이션 로그 오류
# 로그 그룹 선택 : /aws/containerinsights/<CLUSTER_NAME>/application
stats count() as error_count by kubernetes.container_name
| filter stream="stderr"
| sort error_count desc
# All Kubelet errors/warning logs for for a given EKS worker node
# 로그 그룹 선택 : /aws/containerinsights/<CLUSTER_NAME>/dataplane
fields @timestamp, @message, ec2_instance_id
| filter message =~ /.*(E|W)[0-9]{4}.*/ and ec2_instance_id="<YOUR INSTANCE ID>"
| sort @timestamp desc
# Kubelet errors/warning count per EKS worker node in the cluster
# 로그 그룹 선택 : /aws/containerinsights/<CLUSTER_NAME>/dataplane
fields @timestamp, @message, ec2_instance_id
| filter message =~ /.*(E|W)[0-9]{4}.*/
| stats count(*) as error_count by ec2_instance_id
# performance 로그 그룹
# 로그 그룹 선택 : /aws/containerinsights/<CLUSTER_NAME>/performance
# 노드별 평균 CPU 사용률
STATS avg(node_cpu_utilization) as avg_node_cpu_utilization by NodeName
| SORT avg_node_cpu_utilization DESC
# 파드별 재시작(restart) 카운트
STATS avg(number_of_container_restarts) as avg_number_of_container_restarts by PodName
| SORT avg_number_of_container_restarts DESC
# 요청된 Pod와 실행 중인 Pod 간 비교
fields @timestamp, @message
| sort @timestamp desc
| filter Type="Pod"
| stats min(pod_number_of_containers) as requested, min(pod_number_of_running_containers) as running, ceil(avg(pod_number_of_containers-pod_number_of_running_containers)) as pods_missing by kubernetes.pod_name
| sort pods_missing desc
# 클러스터 노드 실패 횟수
stats avg(cluster_failed_node_count) as CountOfNodeFailures
| filter Type="Cluster"
| sort @timestamp desc
# 파드별 CPU 사용량
stats pct(container_cpu_usage_total, 50) as CPUPercMedian by kubernetes.container_name
| filter Type="Container"
| sort CPUPercMedian desc
메트릭 확인
CloudWatch → Insights → Container Insights : 우측 상단(Local Time Zone, 30분) ⇒ 리소스 : myeks 선택 아래의 이미지와 같이 메트릭을 시각화해서 컨테이너의 성능을 측정할 수 있습니다.
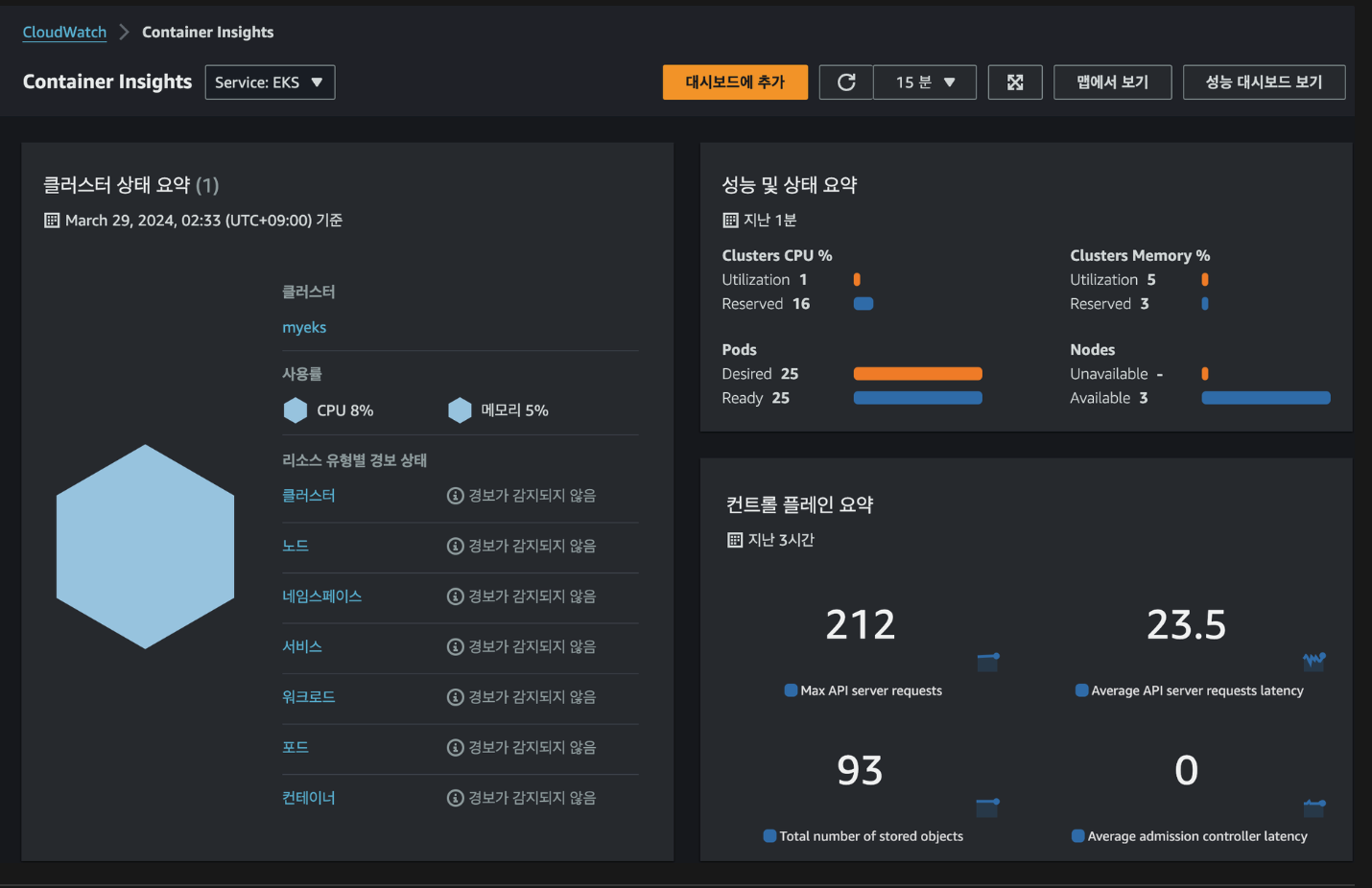
Metrics-server & kwatch & botkube
Metrics-server 확인: kubelet으로부터 수집한 리소스 메트릭을 수집 및 집계하는 클러스터 애드온 구성 요소 - EKS Github Docs CMD
cAdvisor : kubelet에 포함된 컨테이너 메트릭을 수집, 집계, 노출하는 데몬
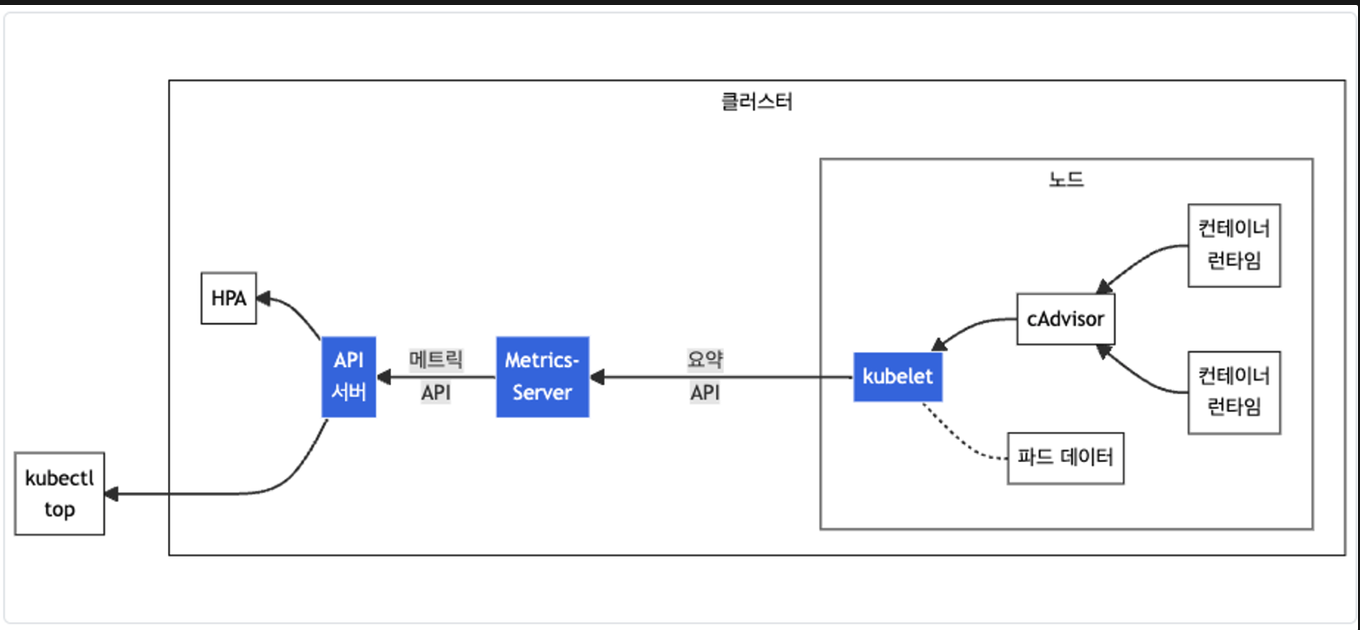
# 배포
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
# 메트릭 서버 확인 : 메트릭은 15초 간격으로 cAdvisor를 통하여 가져옴
kubectl get pod -n kube-system -l k8s-app=metrics-server
kubectl api-resources | grep metrics
kubectl get apiservices |egrep '(AVAILABLE|metrics)'
# 노드 메트릭 확인
kubectl top node
# 파드 메트릭 확인
kubectl top pod -A
kubectl top pod -n kube-system --sort-by='cpu'
kubectl top pod -n kube-system --sort-by='memory'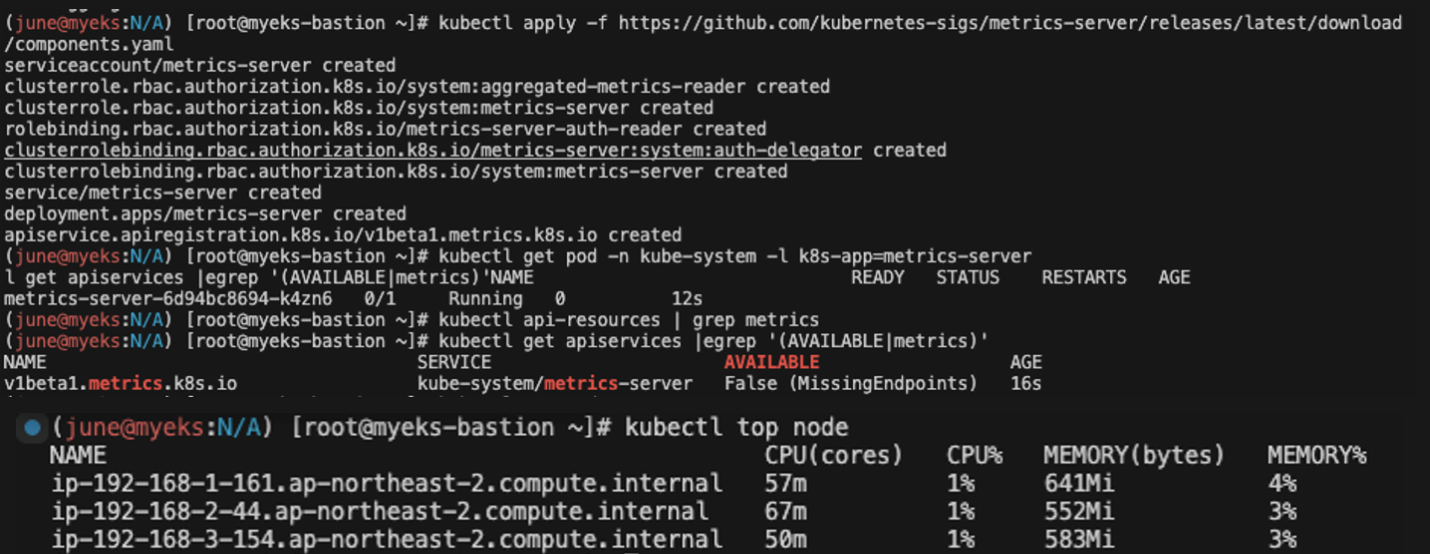
Kubernetes 메트릭 서버(metrics-server)를 설치하기 위해 공식 GitHub 저장소에서 최신 **components.yaml**을 적용했습니다. 클러스터 내 리소스 사용량(예: CPU, 메모리)을 측정하는데 필요한 서비스입니다.
메트릭 서버가 제공하는 API 서비스의 상태를 확인했을 때 AVAILABLE 상태가 **False (MissingEndpoints)**로 되어 있었습니다. 이는 메트릭 서버가 아직 완전히 구성되지 않아 사용할 준비가 되지 않았음을 의미합니다.
잠시 후, 메트릭 서버가 정상적으로 동작하기 시작하고, kubectl top node 명령을 통해 노드별 CPU 및 메모리 사용량을 성공적으로 확인할 수 있게 되었습니다.
kubectl top pod -A 및 kubectl top pod -n kube-system --sort-by='cpu' 명령을 사용하여 클러스터 전체 또는 특정 네임스페이스 내의 포드별 CPU 및 메모리 사용량을 확인했습니다. 이를 통해 클러스터 내 리소스 사용 패턴을 모니터링 할 수 있습니다.
Kubernetes 클러스터 내에서 리소스 사용량을 모니터링하기 위해 메트릭 서버를 성공적으로 설치하고 활용할 수 있게 되었습니다.
kwatch 소개 및 설치/사용
kwatch는 Kubernetes 클러스터의 모든 변경 사항을 모니터링하고, 실행 중인 앱의 충돌을 실시간으로 감지하여 채널에 알림(슬랙, 디스코드 등)을 즉시 보내 인지할 수 있도록 도와주는 툴입니다.
# configmap 생성
cat <<EOT > ~/kwatch-config.yaml
apiVersion: v1
kind: Namespace
metadata:
name: kwatch
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
namespace: kwatch
data:
config.yaml: |
alert:
slack:
webhook: 'https://hooks.slack.com/services/<Slack Webhook url>'
title: $NICK-EKS
#text: Customized text in slack message
pvcMonitor:
enabled: true
interval: 5
threshold: 70
EOT
kubectl apply -f kwatch-config.yaml
# 배포
kubectl apply -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8.5/deploy/deploy.yaml
잘못된 nginx이미지 배포
# 터미널1
watch kubectl get pod
# 잘못된 이미지 정보의 파드 배포
kubectl apply -f https://raw.githubusercontent.com/junghoon2/kube-books/main/ch05/nginx-error-pod.yml
kubectl get events -w
# 이미지 업데이트 방안2 : set 사용 - iamge 등 일부 리소스 값을 변경 가능!
kubectl set
kubectl set image pod nginx-19 nginx-pod=nginx:1.19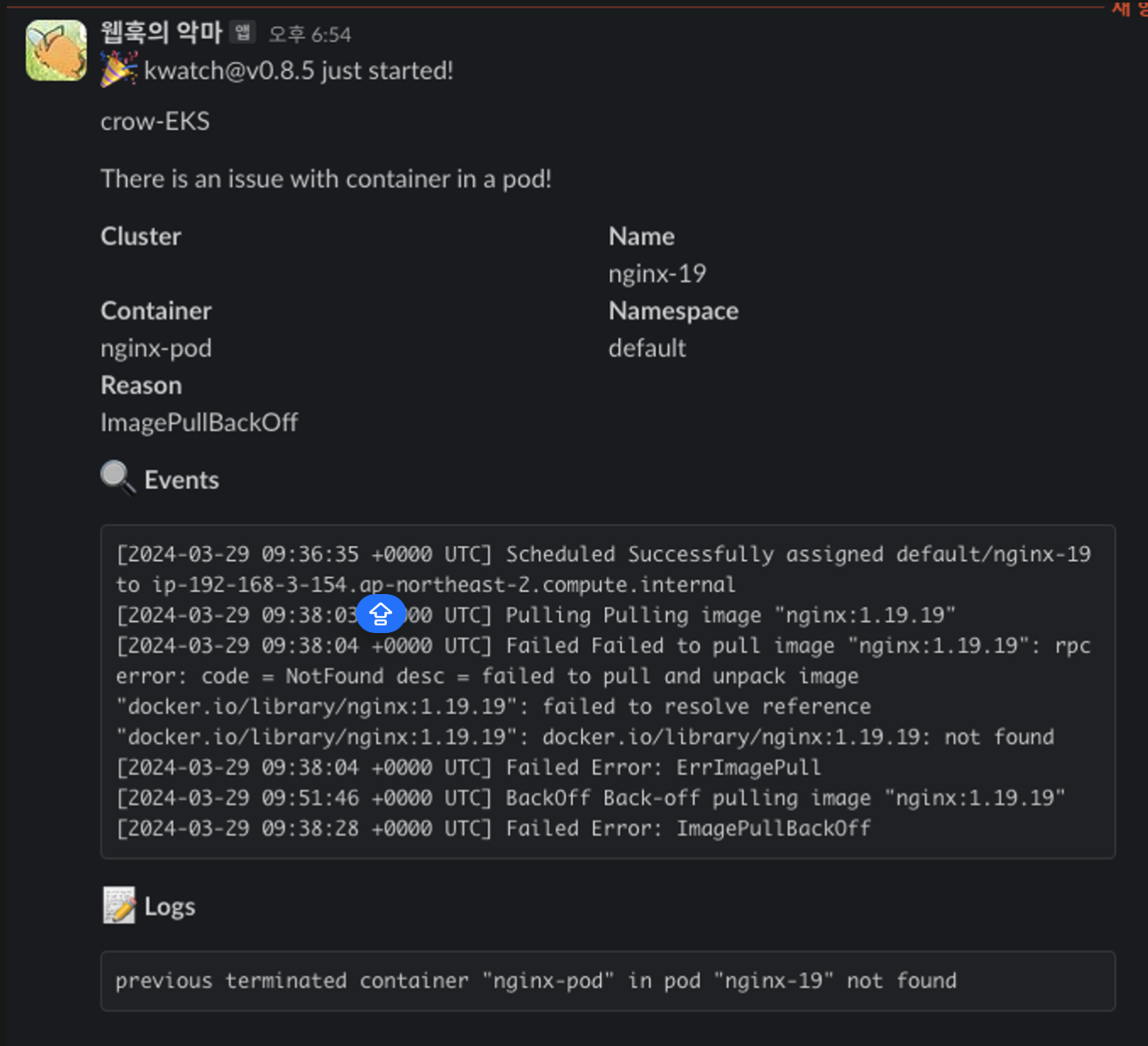
잘못된 이미지 배포 후 다음과 같이 슬랙에 웹훅을 잘 던져주는 것을 확인할 수 있습니다.
클린업
kubectl delete -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8./deploy/deploy.yamlbotkube 공홈 Blog Youtube
botkube는 클러스터에서 발생하는 오류를 수집해서 메신저로 알림을 보내주는 프로그램입니다.
botkube는 슬랙 채널에서 쿠버네티스 명령어를 실행가능한 장점이 있습니다. .
슬랙에 앱을 설치해서 진행했습니다. → https://docs.botkube.io/installation/slack/socket-slack
슬랙 봇 토큰과 앱 토큰을 환경변수로 설정해줍니다.
export SLACK_API_BOT_TOKEN='xoxb-YYYY'
export SLACK_API_APP_TOKEN='xapp-YYYXXXXX'
helm repo 를 추가해줍니다.
helm repo add botkube https://charts.botkube.io
helm repo update
환경변수를 추가해줍니다.
export ALLOW_KUBECTL=true
export ALLOW_HELM=true
export SLACK_CHANNEL_NAME='10_chapter_automation_test'

봇을 채널에 초대해줍니다. (초대안하고 했다가 좀 혼란스러웠네요 ㅜ)
yaml 파일을 이용해서 botkube 의 슬랙에서 kubectl 을 사용할 수 있도록 설정해주었습니다.
actions:
'describe-created-resource': # kubectl describe
enabled: true
'show-logs-on-error': # kubectl logs
enabled: true
executors:
k8s-default-tools:
botkube/helm:
enabled: true
botkube/kubectl:
enabled: true
helm install --version v1.0.0 botkube --namespace botkube --create-namespace \\
--set communications.default-group.socketSlack.enabled=true \\
--set communications.default-group.socketSlack.channels.default.name=${SLACK_CHANNEL_NAME} \\
--set communications.default-group.socketSlack.appToken=${SLACK_API_APP_TOKEN} \\
--set communications.default-group.socketSlack.botToken=${SLACK_API_BOT_TOKEN} \\
--set settings.clusterName=${CLUSTER_NAME} \\
--set 'executors.k8s-default-tools.botkube/kubectl.enabled'=${ALLOW_KUBECTL} \\
--set 'executors.k8s-default-tools.botkube/helm.enabled'=${ALLOW_HELM} \\
-f botkube-values.yaml botkube/botkube
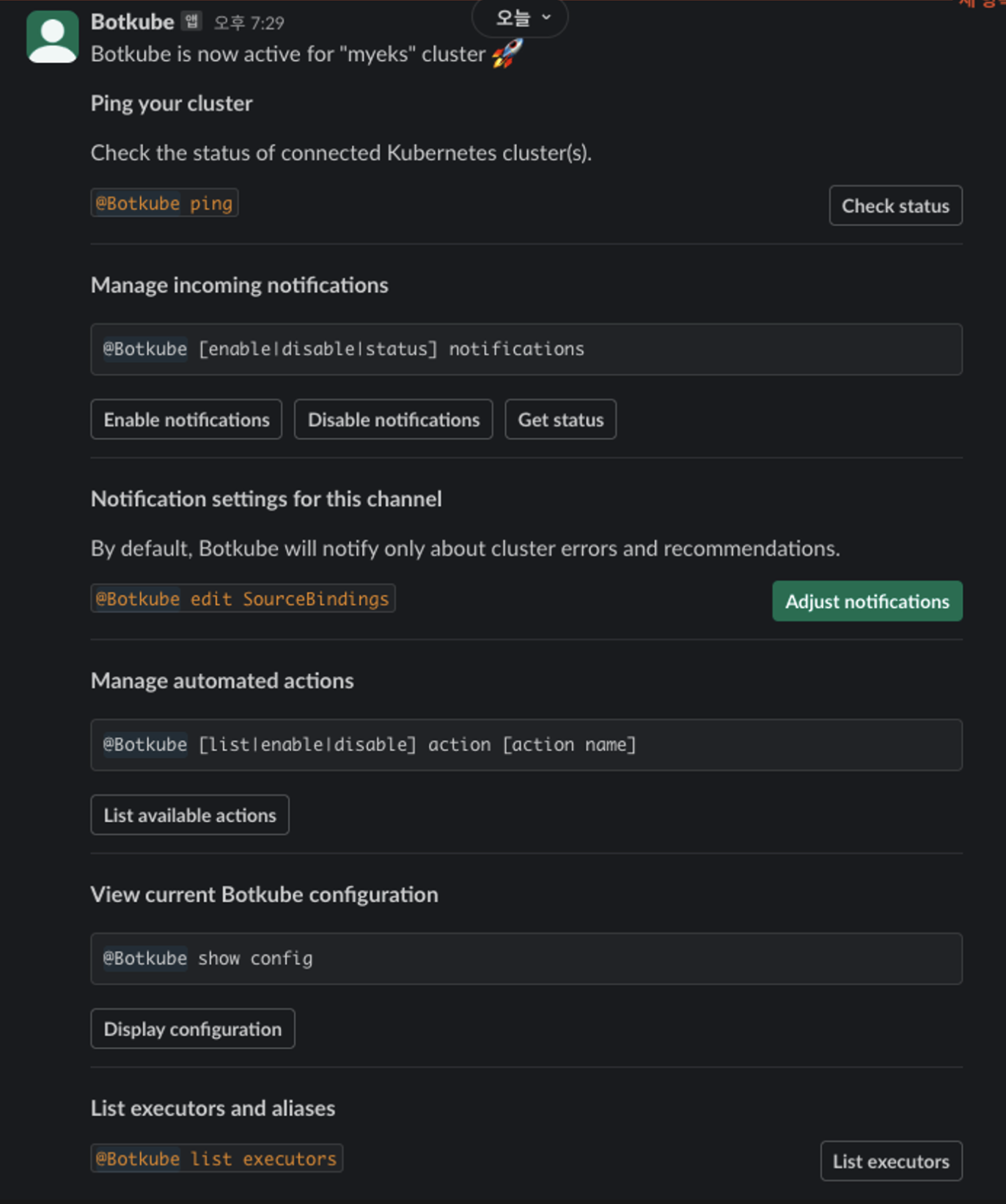
배포가 정상적이면 해당 메세지들이 옵니다.
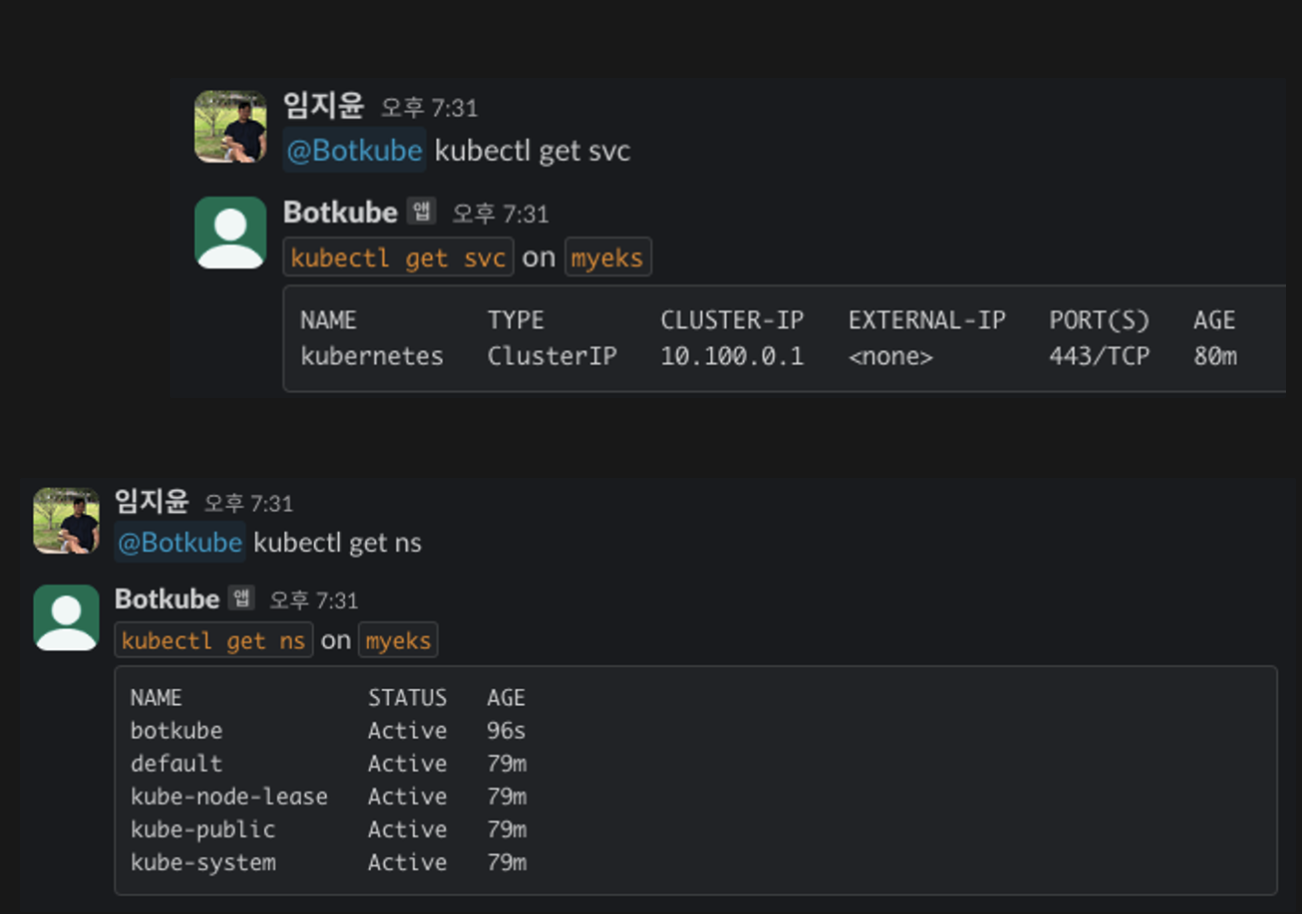
오우…. kubectl 명령이 슬랙으로도 가능합니다. 숙련되면 침대에서도 관리가 가능하겠는데요
클린업
helm uninstall botkube --namespace botkube
프로메테우스-스택
Prometheus는 오픈 소스 시스템 모니터링 및 알림 도구 키트로, 원래 SoundCloud에서 개발되었습니다.
시스템의 상태를 실시간으로 모니터링하고, 시계열 데이터(Time Series Data)를 기반으로 다양한 지표(Metrics)를 수집, 저장, 분석할 수 있습니다.
Prometheus의 주요 특징과 제공 기능은 다음과 같습니다:
다차원 데이터 모델: Prometheus는 시계열 데이터베이스(TSDB)를 사용하여, 메트릭 이름과 키/값 쌍으로 식별되는 다차원 데이터 모델을 제공합니다. 이를 통해 사용자는 시간에 따라 변하는 다양한 시스템 지표를 효율적으로 저장하고 관리할 수 있습니다.
PromQL: 이는 Prometheus의 유연한 쿼리 언어로, 다차원 데이터를 활용하여 복잡한 시계열 데이터 분석 및 질의를 수행할 수 있습니다. PromQL을 사용하면 시간 범위, 데이터 집계, 라벨에 기반한 필터링 등 다양한 데이터 조회 및 분석 작업을 할 수 있습니다.
분산 스토리지에 대한 의존성 없음: Prometheus는 분산 스토리지 시스템에 의존하지 않으며, 단일 서버 노드가 자체적으로 독립적으로 운영됩니다. 이로 인해 간단한 설정으로 빠르게 모니터링 시스템을 구축하고 운영할 수 있습니다.
데이터 수집 방식: Prometheus는 주로 HTTP를 통한 Pull 방식으로 시계열 데이터를 수집합니다. 이는 Prometheus 서버가 설정된 주기에 따라 각 대상(Target)에서 데이터를 직접 가져오는 방식입니다. 이와 대조적으로 Push 방식은 데이터 소스가 데이터를 서버로 직접 전송하는 방식으로, Prometheus에서는 Pushgateway라는 중간 게이트웨이를 통해 Push 방식의 데이터 수집도 지원합니다.
서비스 발견 및 정적 설정을 통한 대상 발견: Prometheus는 서비스 디스커버리(Service Discovery) 또는 정적(Static) 구성을 통해 모니터링할 대상을 자동으로 찾아내고 관리할 수 있습니다. 이를 통해 동적인 클라우드 환경에서도 효율적으로 리소스를 모니터링할 수 있습니다.
다양한 시각화 및 대시보드 지원: Prometheus는 다양한 시각화 표현과 대시보드를 지원하여, 수집된 데이터를 시각화하고 분석할 수 있는 기능을 제공합니다. Grafana와 같은 외부 도구와 연동하여 더욱 풍부한 데이터 시각화 및 대시보드를 구성할 수 있습니다.
Push와 Pull 수집 방식의 장단점
Pull 방식의 장점은 모니터링 시스템이 능동적으로 대상 시스템의 상태를 확인할 수 있으며, 네트워크 문제나 대상 시스템의 장애 상황에서도 데이터 수집의 누락을 최소화할 수 있다는 점입니다. 또한, 보안적인 측면에서도 데이터 소스의 인증 및 권한 관리가 용이합니다. 단점으로는 대상 시스템에 추가적인 구성이 필요없는 Push 방식에 비해 설정이 복잡할 수 있으며, 실시간성이 덜 요구되는 환경에서는 불필요한 리소스 소모가 발생할 수 있습니다.
Push 방식의 장점은 구성의 단순성과 대상 시스템에서 발생하는 이벤트를 실시간으로 수집할 수 있다는 점입니다. 이는 특히 이벤트 기반의 모니터링이 필요한 환경에서 유리할 수 있습니다. 단점으로는 모니터링 시스템에 과부하가 발생할 수 있으며, 네트워크 문제나 서버의 장애 시 데이터 손실 위험이 존재합니다.
구성요소
프로메테우스는 여러 구성요소로 이루어진 모니터링 및 알림 시스템입니다.
핵심 구성요소로는 시계열 데이터를 수집 및 저장하는 프로메테우스 서버, 애플리케이션 코드를 수집하는 클라이언트 라이브러리, 짧은 작업을 위한 푸시 게이트웨이, 다양한 서비스(예: HAProxy, StatsD)를 위한 전용 익스포터, 알림을 처리하는 알럿매니저 등이 있습니다.
이 구성요소들은 서로 협력하여 애플리케이션과 인프라의 성능을 모니터링하고 문제가 발생했을 때 알림을 제공합니다.
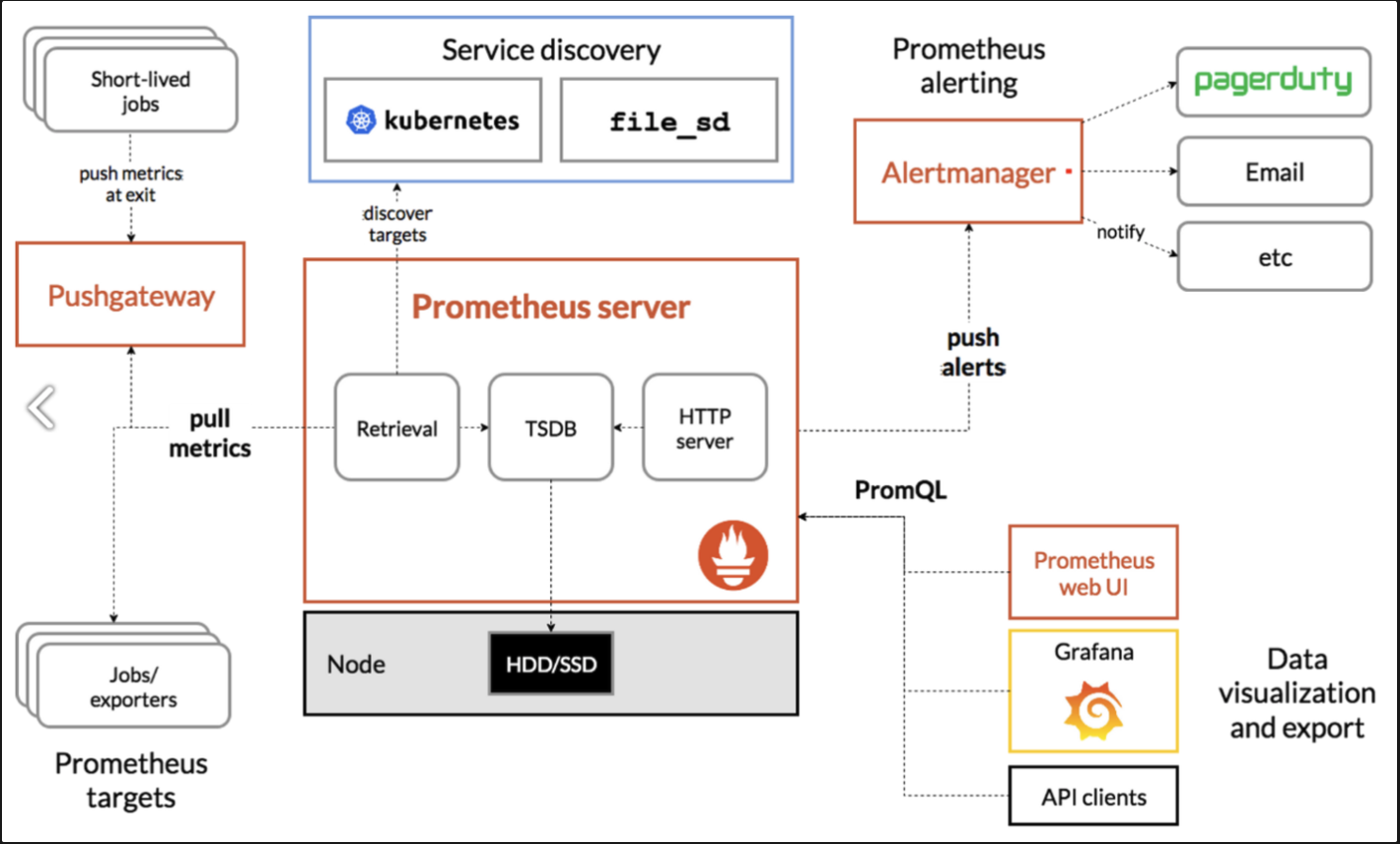
프로메테우스 오퍼레이터
Prometheus Operator를 사용하면 Kubernetes에서 Prometheus와 관련 모니터링 구성 요소를 쉽게 배포하고 관리할 수 있습니다.
- 맞춤형 리소스 정의(CRD): 사용자가 Prometheus와 AlertManager 인스턴스를 선언적으로 구성하고 관리할 수 있게 해줍니다.
- ServiceMonitor: 서비스 발견을 자동화하여, 수동으로 모니터링할 서비스를 지정하는 대신 ServiceMonitor 리소스를 통해 자동으로 검색하게 합니다.
- AlertManager 구성: Prometheus로부터 발생하는 알림을 관리하고, 이를 처리합니다.
- 자동 구성 업데이트: Prometheus 또는 AlertManager의 구성 변경 시, 자동으로 업데이트하여 새로운 설정을 적용합니다.
이런 방식으로 Prometheus Operator는 Kubernetes 환경에서 모니터링 시스템의 관리를 용이하게 만들어줍니다.
프로메테우스-스택 설치
모니터링에 필요한 여러 요소를 **단일 차트(스택)**으로 제공 ← 시각화(그라파나), 이벤트 메시지 정책(경고 임계값, 경고 수준) 등 - Helm
주요 파드들은 EBS 스토리지 클래스를 사용할 수 있게 helm 파라미터를 변경하는 실습을 합니다.
# 모니터링
kubectl create ns **monitoring**
watch kubectl get pod,pvc,svc,ingress -n monitoring
# 사용 리전의 인증서 ARN 확인 : 정상 상태 확인(만료 상태면 에러 발생!)
**CERT_ARN=`aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text`**
echo $CERT_ARN
****# repo 추가
helm repo add prometheus-community <https://prometheus-community.github.io/helm-charts>

정상적으로 인증서를 확인했고, 프로메테우스 repo를 추가했습니다.
파라미터 파일을 생성 해줍니다.
cat <<EOT > monitor-values.yaml
**prometheus**:
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
**storageSpec**:
volumeClaimTemplate:
spec:
storageClassName: **gp3**
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 30Gi
ingress:
enabled: true
ingressClassName: alb
hosts:
- prometheus.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
**alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'**
**grafana**:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
hosts:
- grafana.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
**alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'**
**persistence**:
enabled: true
type: sts
storageClassName: "gp3"
accessModes:
- ReadWriteOnce
size: 20Gi
**defaultRules:
create: false**
**kubeControllerManager:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false**
**alertmanager:
enabled: false**
EOT
monitor-values.yaml 파일은 특정 저장소, 인그레스, 모니터링 설정을 사용하여 Prometheus와 Grafana를 구성합니다.
- prometheus: Prometheus 설정, 데이터 보존 기간(retention, retentionSize), 저장소 사양(storageSpec)을 정의합니다. 여기서 gp3 스토리지 클래스와 30Gi 저장 공간을 요구합니다.
- ingress: ALB를 사용하여 Prometheus와 Grafana에 대한 인터넷 액세스를 설정합니다. HTTPS와 HTTP 모두를 지원하며, 인증서 ARN과 성공 코드를 지정합니다.
- grafana: Grafana 설정, 시간대(defaultDashboardsTimezone), 관리자 비밀번호(adminPassword), 영속성(persistence)을 정의합니다. 여기서는 20Gi 저장 공간을 사용하고, gp3 스토리지 클래스를 요구합니다.
- defaultRules, kubeControllerManager, kubeEtcd, kubeScheduler, alertmanager: 각각 기본 규칙 생성을 비활성화하고, 쿠버네티스 컨트롤러 매니저, etcd, 스케줄러, Alertmanager의 모니터링을 비활성화하여 운영을 간소화합니다.
배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version **57.1.0** \\
--**set** prometheus.prometheusSpec.scrapeInterval='15s' --**set** prometheus.prometheusSpec.evaluationInterval='15s' \\
-f **monitor-values.yaml** --namespace monitoring
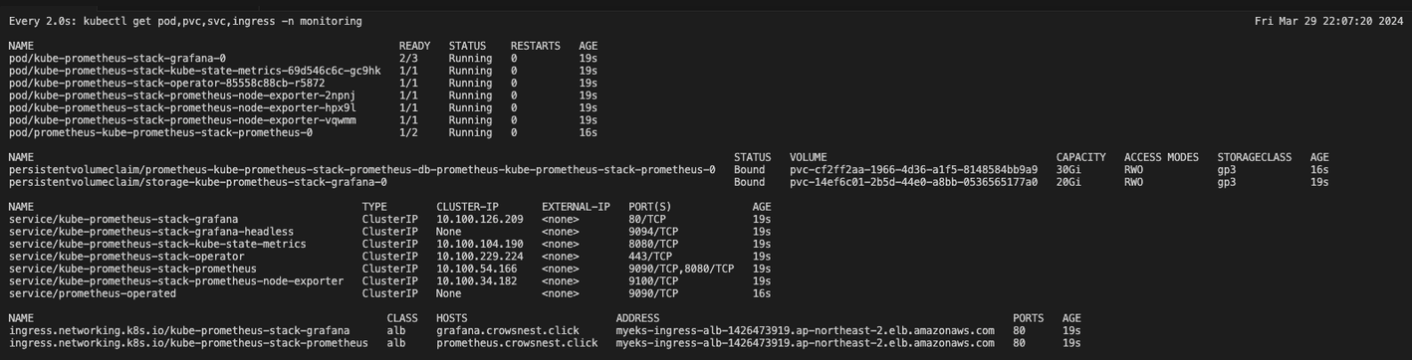
kube-prometheus-stack'을 이용해서, 모니터링 시스템을 설치했습니다.'monitoring'이라는 네임스페이스 안에 모든 것이 잘 설정되었어. 이제 '그라파나'와 대시보드와 '프로메테우스’를 사용해 시스템의 상태를 시각적으로 쉽게 확인할 수 있게 됩니다.
pod/prometheus-kube-prometheus-stack-prometheus-0
pod/kube-prometheus-stack-grafana-0
각각 그라파나와 프로메테우스 서버입니다.
AWS EC2콘솔에서 확인한 로드밸런서입니다.

yaml 파일에 기입된대로 alb가 생성 되었습니다.
여기서 특이한점은
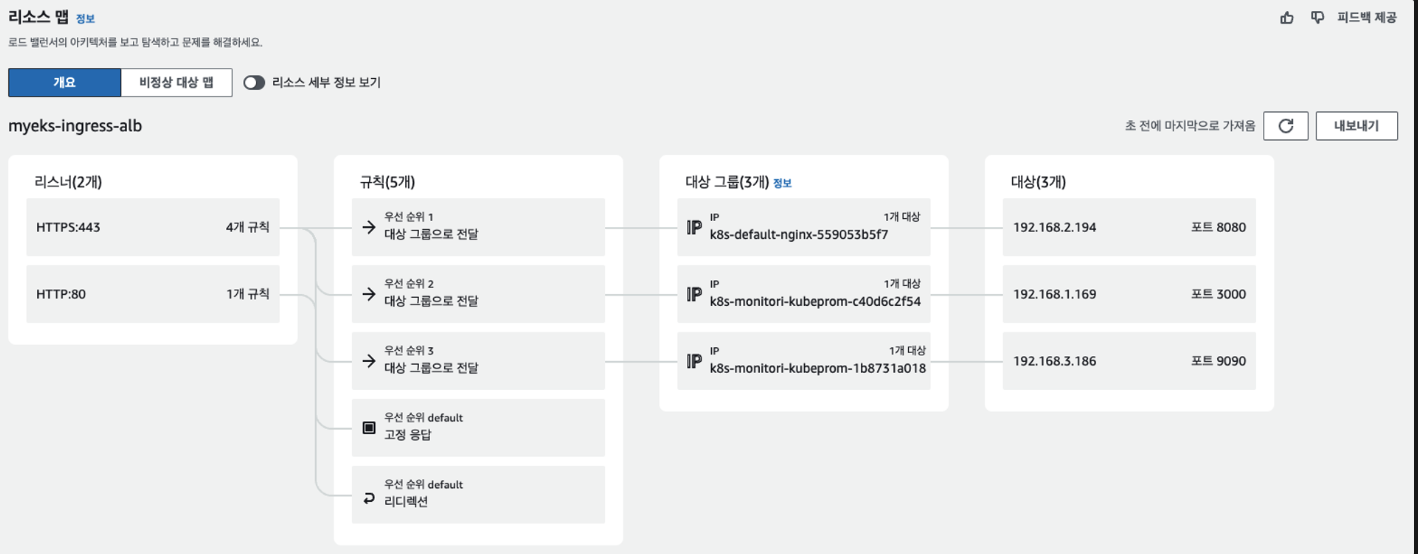
하나는 그라파나 하나는 프로메테우스에 연결되어있습니다. 그리고 다른 하나는 Nginx에 연결되어있습니다.
하지만 로드 밸런서는 하나를 사용하고있습니다. 어떻게 이게 가능하게 되는걸까요?
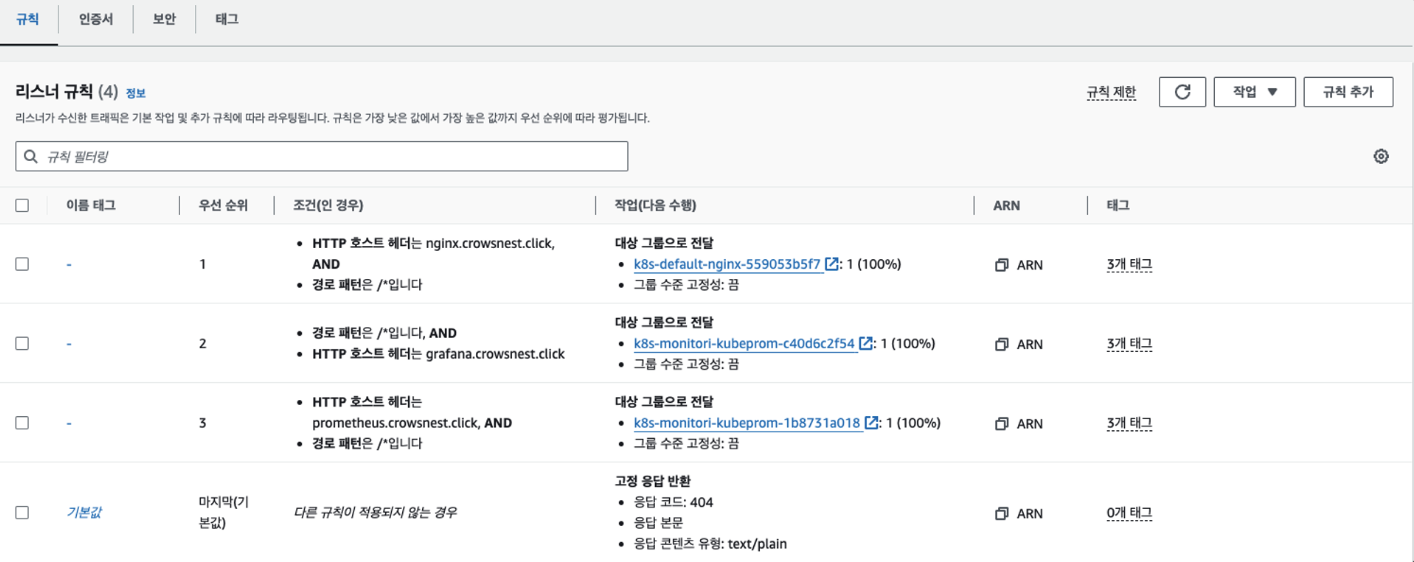
해당 로드밸런서의 리스너 규칙을 확인합니다.
- nginx.crowsnest.click
- grafana.crowsnest.click
- prometheus.crowsnest.click
위 세 도메인에 대한 접근에 대해 동일한 alb더라도 각기 다른 대상그룹으로 보냅니다.
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study위 두 설정이 이를 가능하게 합니다.
Kubernetes Ingress 리소스와 관련이 있습니다.
alb.ingress.kubernetes.io/load-balancer-name는 AWS Application Load Balancer(ALB)에 사용될 이름을 지정합니다.
여기서는 'myeks-ingress-alb'라는 이름이 지정되어 있습니다.
alb.ingress.kubernetes.io/group.name는 ALB 리소스를 논리적으로 그룹화하기 위해 사용되는 이름입니다.
여기서는 'study'라는 그룹 이름이 할당되어 있어, 관련 리소스들이 'study' 그룹에 속하게 됩니다.
이 덕에 호스트의 경로 패턴으로 구분될 수 있게 됩니다.
프로메테우스 기본 사용 : 모니터링 그래프
kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus-node-exporter

노드의 정보를 프로메테우스가 가져갈 수 있도록 하는것입니다.
ssh ec2-user@$N1 curl -s localhost:**9100**/metrics
노드에 수집되는 정보들을 확인할 수 있습니다.
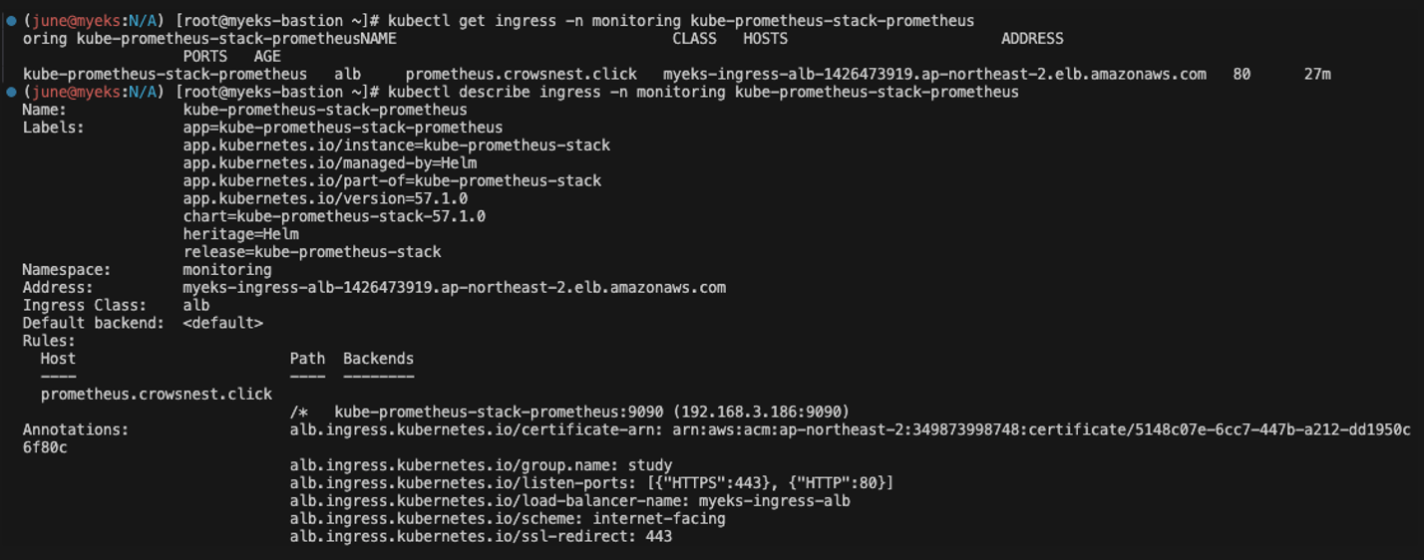
프로메테우스 ingress 도메인으로 웹 접속
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-prometheus
kubectl describe ingress -n monitoring kube-prometheus-stack-prometheus
# 프로메테우스 ingress 도메인으로 웹 접속
echo -e "Prometheus Web URL = <https://prometheus.$MyDomain>"
https://prometheus.crowsnest.click/ 로 접속하면 프로메테우스 콘솔에 들어갈 수 있습니다.
# 웹 상단 주요 메뉴 설명
1. 경고(Alert) : 사전에 정의한 시스템 경고 정책(Prometheus Rules)에 대한 상황
2. 그래프(Graph) : 프로메테우스 자체 검색 언어 PromQL을 이용하여 메트릭 정보를 조회 -> 단순한 그래프 형태 조회
3. 상태(Status) : 경고 메시지 정책(Rules), 모니터링 대상(Targets) 등 다양한 프로메테우스 설정 내역을 확인 > 버전(2.42.0)
4. 도움말(Help)
프로메테우스 사용하기
모니터링 대상이 되는 서비스는 자체 웹 서버의 /metrics 엔드포인트로 메트릭 정보를 노출합니다.
프로메테우스는 해당 경로에 HTTP GET 요청을 전송해서 메트릭 정보를 가져오고, 시계열 데이터베이스 형태로 저장합니다.
각 워커 노드에 ssh로 직접 접속해서 localhost:9100/metrics 로 GET 요청을 보내면 다음처럼 메트릭 정보를 확인할 수 있습니다.
# 1번 워커노드
ssh ec2-user@$N1 curl -s localhost:9100/metrics | tail -n 3

# 2번 워커노드
ssh ec2-user@$N2 curl -s localhost:9100/metrics | tail -n 3
Status - Target
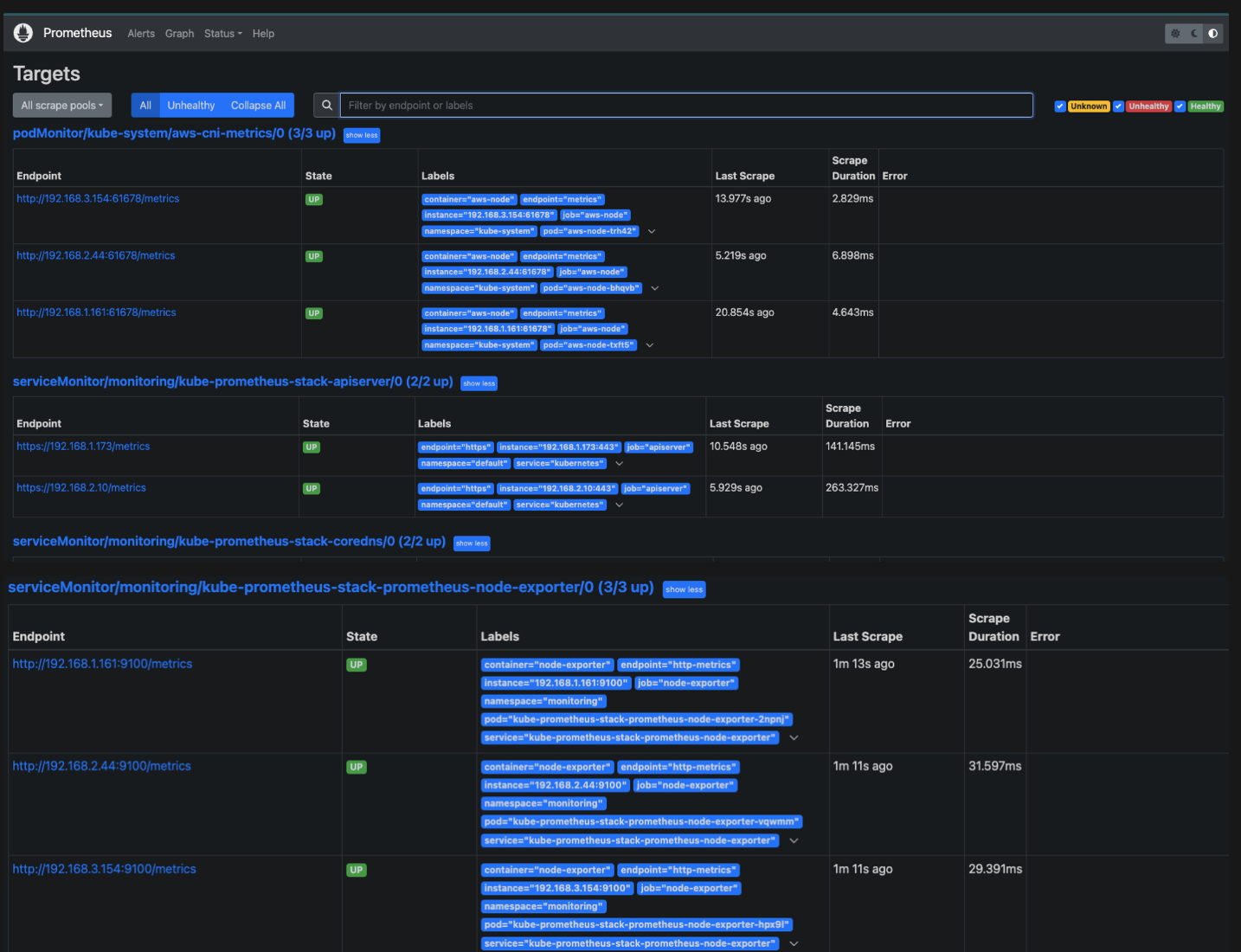
해당 스택은 ‘node exporter’, cAdvisor, 쿠버네티스 전반적인 현황 이외에 다양한 메트릭을 포함합니다.
node exporter는 9100번대 포트를 사용하니, 9100번에 접근을 하면 해당 노드의 정보를 가져올 수 있게 되는것입니다.
서비스 디스커버리
프로메테우스 설정(Configuration) 확인 : Status → Service Discovery
모든 endpoint 로 도달 가능시 자동 발견하여 메트릭 수집 대상으로 등록합니다.
도달 규칙은 설정Configuration 파일에 정의합니.
kubenetes api 를 이용해서 실행 중인 모든 서비스와 엔드포인트를 검색할 수 있다.
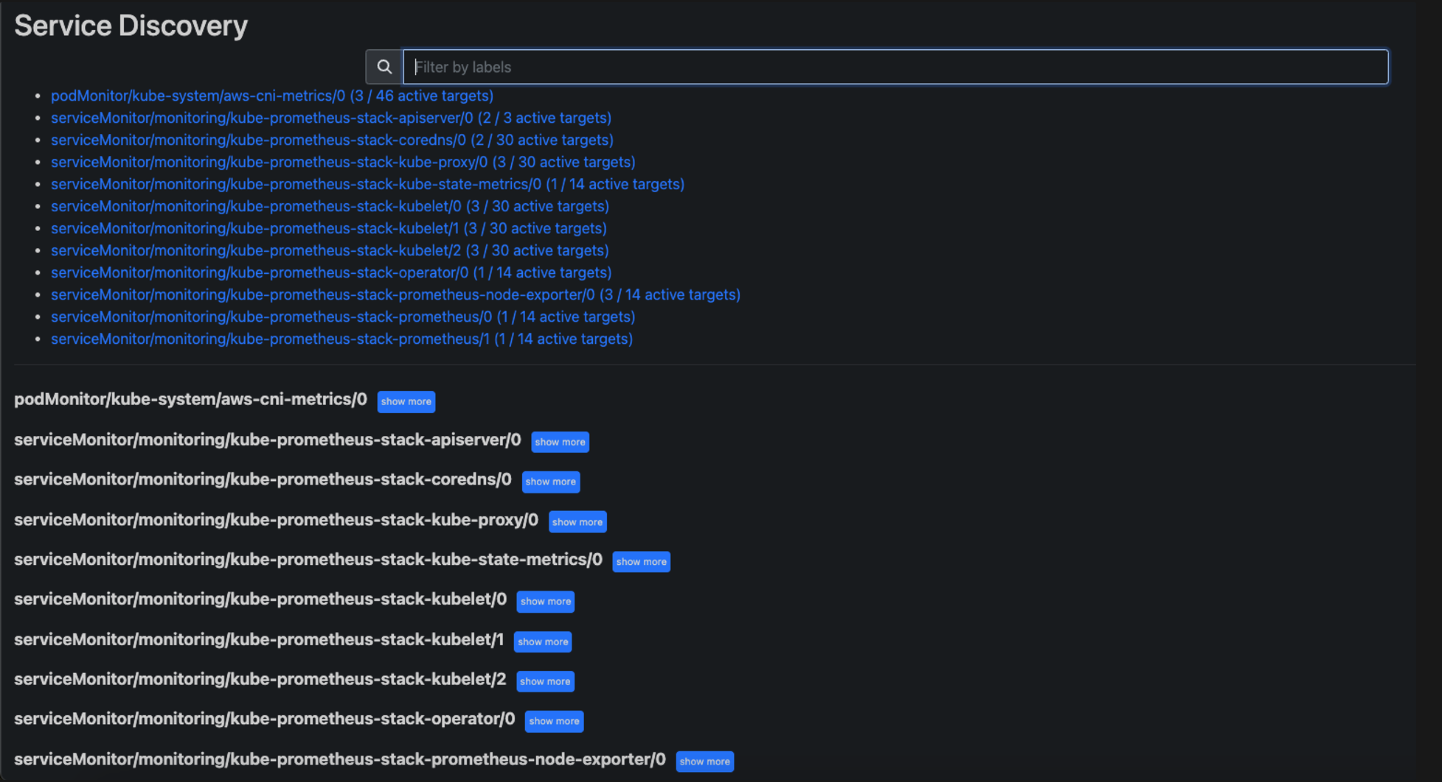
AWS CNI Metrics 을 수집하기 위한 PodMonitor 를 아까 배포했는것도 자동으로 가져와서 이미
podMonitor/kube-system/aws-cni-metrics/0 이렇게 추가되어있는것 확인 가능합니다.
PromQL
프로메테우스는 메트릭을 가공해서 조회할 수 있는 자체 쿼리 언어인 PromQL(Prometheus Query Language)를 지원합니다.
- 메트릭을 그래프(Graph)로 조회 : Graph - 아래 PromQL 쿼리(전체 클러스터 노드의 CPU 사용량 합계)입력 후 조회 → Graph 확인

1- avg(rate(node_cpu_seconds_total{mode="idle"}[1m]))
노드의 cpu 가 idle 상태에 있던 시간의 평균값을 1분 단위로 조회하는 쿼리입니다.
메트릭(metric)이란 측정 가능한 어떤 값이나 정보를 의미하며, 프로메테우스에서는 이러한 메트릭을 관리하고 분석하기 위해 네 가지 기본 타입을 제공합니다.
1. 게이지(Gauge)
게이지는 특정 시점에서의 값을 측정하기 위한 메트릭입니다. 이 값은 증가하거나 감소할 수 있으며, 시스템의 현재 상태를 나타내는 데 사용됩니다. 예를 들어, CPU의 현재 온도나 시스템의 메모리 사용량 같은 것이 이에 해당합니다. 게이지는 순간적인 값 변화를 관찰하고자 할 때 유용합니다.
2. 카운터(Counter)
카운터는 누적되는 값을 표현하기 위해 사용되는 메트릭입니다. 이 값은 오직 증가만 할 수 있으며, 일정 시간 동안 발생한 이벤트의 수를 측정하는 데 주로 사용됩니다. 예를 들면, 웹 사이트에 대한 요청 처리 횟수나 시스템에서 발생한 오류의 횟수 등이 있습니다. 카운터는 시간에 따른 변화량을 추적하고자 할 때 유용합니다.
3. 히스토그램(Histogram)
히스토그램은 관측된 값들의 분포를 나타내는 메트릭입니다. 이 메트릭은 측정 값들을 여러 범위의 버킷(bucket)으로 분류하고, 각 버킷에 속하는 값들의 빈도수를 측정합니다. 예를 들어, 요청 지연 시간이 얼마나 자주 특정 범위에 속하는지를 분석할 때 사용할 수 있습니다. 히스토그램은 시스템의 성능 분석이나 응답 시간과 같은 메트릭의 분포를 파악하는 데 적합합니다.
4. 요약(Summary)
요약은 히스토그램과 유사하지만, 실시간으로 합계와 카운트를 계산하여 평균, 분산, 분위수 같은 요약 통계를 제공하는 메트릭입니다. 요약은 히스토그램보다 더 복잡한 계산을 수행할 수 있지만, 그만큼 더 많은 리소스를 소모합니다. 요약은 특히, 분포의 정확한 통계치를 실시간으로 파악해야 할 때 사용됩니다.
PromQL과 메트릭 분석
Prometheus는 PromQL이라는 강력한 쿼리 언어를 제공하여, 수집된 메트릭 데이터를 효율적으로 조회하고 분석할 수 있습니다. PromQL을 사용하면, 위에서 설명한 메트릭 타입들을 바탕으로 시스템의 성능을 모니터링하고, 문제를 진단하며, 트렌드를 분석하는 등 다양한 분석 작업을 수행할 수 있습니다.
그라파나
TSDB 데이터를 시각화하는 프로그램입니다. 프로메테우스와 함께 잘 사용되고, 다양한 데이터 형식을 지원합니다.(메트릭, 로그, 트레이스 등)
- 그라파나는 시각화 솔루션으로 데이터 자체를 저장하지 않습니다.
- → 실습 환경에서는 데이터 소스는 프로메테우스를 사용합니다.
접속 정보 확인 및 로그인 : 기본 계정 - admin / prom-operator
위 정보를 사용해서 로그인합니다.
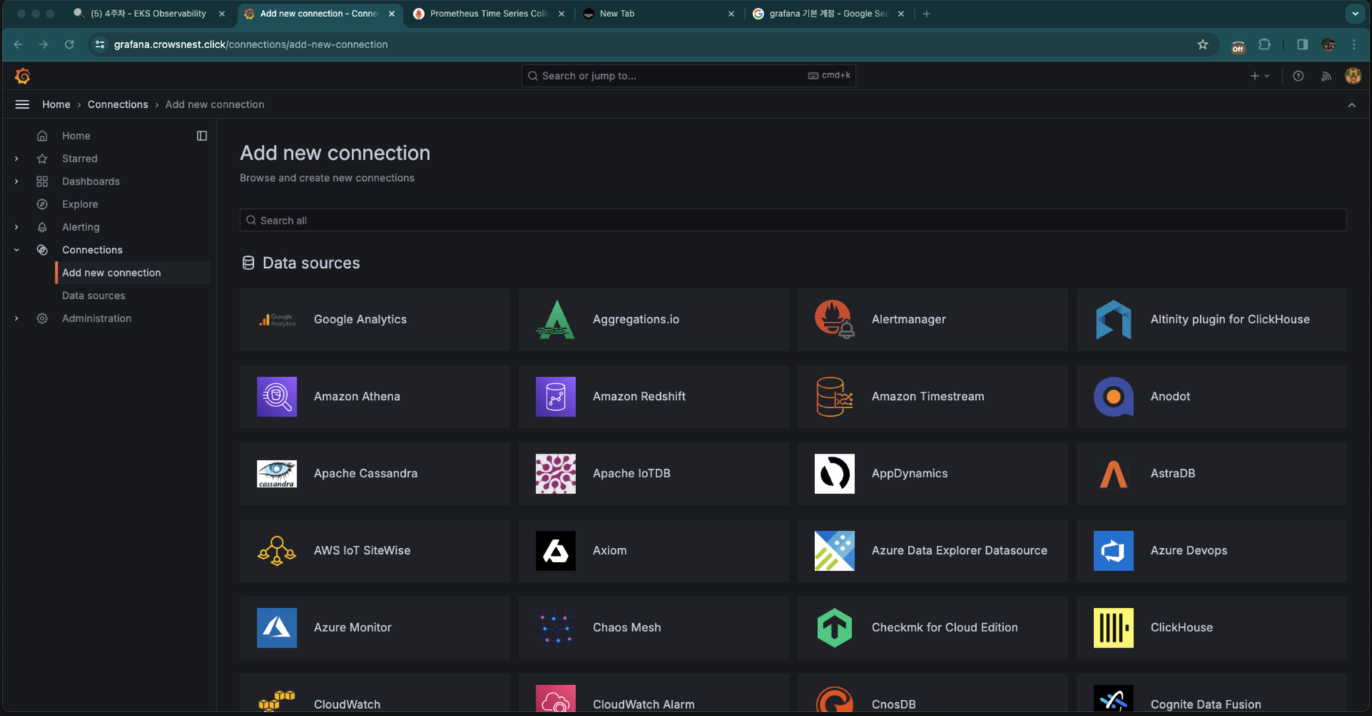
그라파나에서 커넥트에 들어오면 모이는 리소스들과 integration이 가능합니다.
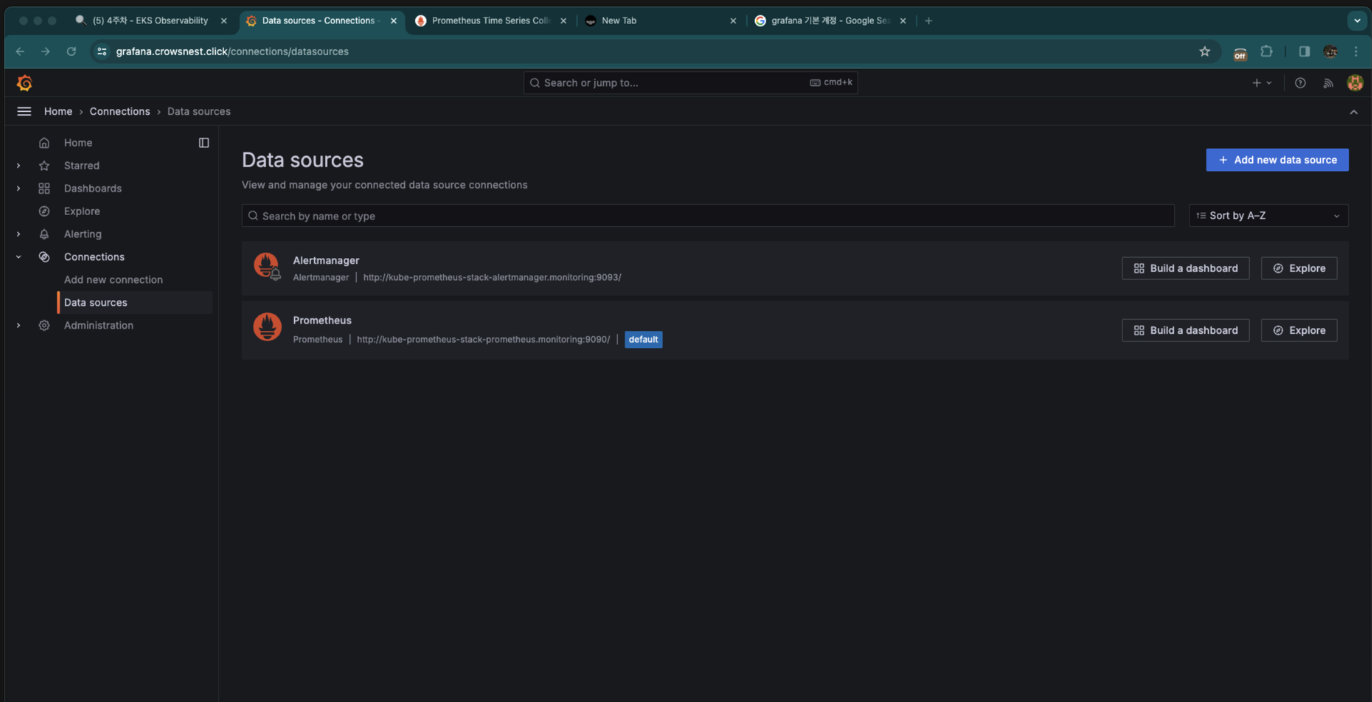
Data source를 보면 디폴트로 이미 프로메테우스가 잡혀있는것을 확인할 수 있습니다.
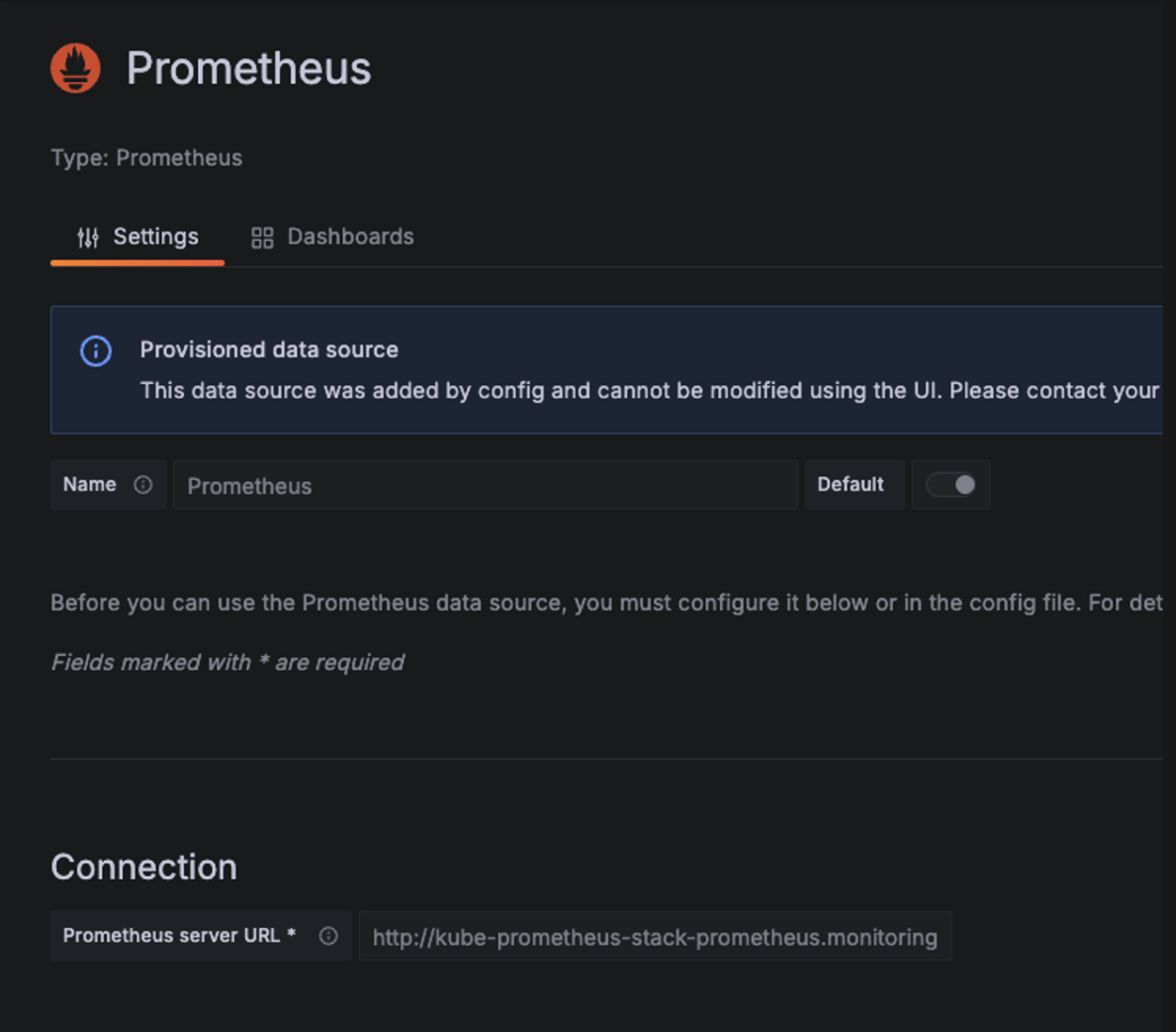
클릭을 하면 connection 부분에서 주소를 확인할 수 있습니다.
위 이름은 어떤 주소일까요?
kubectl get ingress -n monitoring kube-prometheus-stack-prometheus

해당 서비스명 입니다
DashBoards - 우측상단 import를 눌러줍니다.
대시보드의 id 15757을 넣고 load를 눌러줍니다. (17900도 좋다고합니다. )
그리고 소스 데이터에 프로메테우스를 넣어주고 import를 한번 더 눌러줍니다.
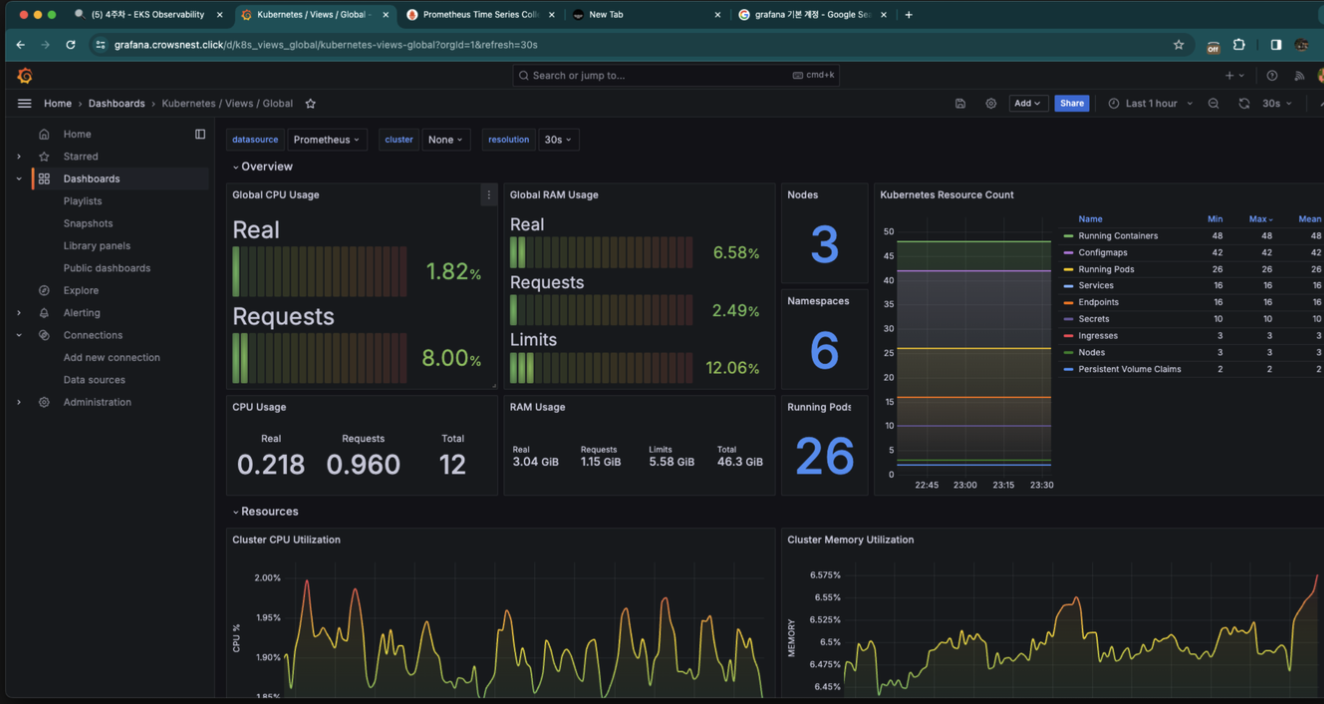
그러면 이렇게 구성되어있는 대시보드가 나옵니다.
그라파나 알림 설정하기
Alerting을 눌러줍니다.
Alert rules를 클릭합니다.
New alert rule을 클릭해줍니다.
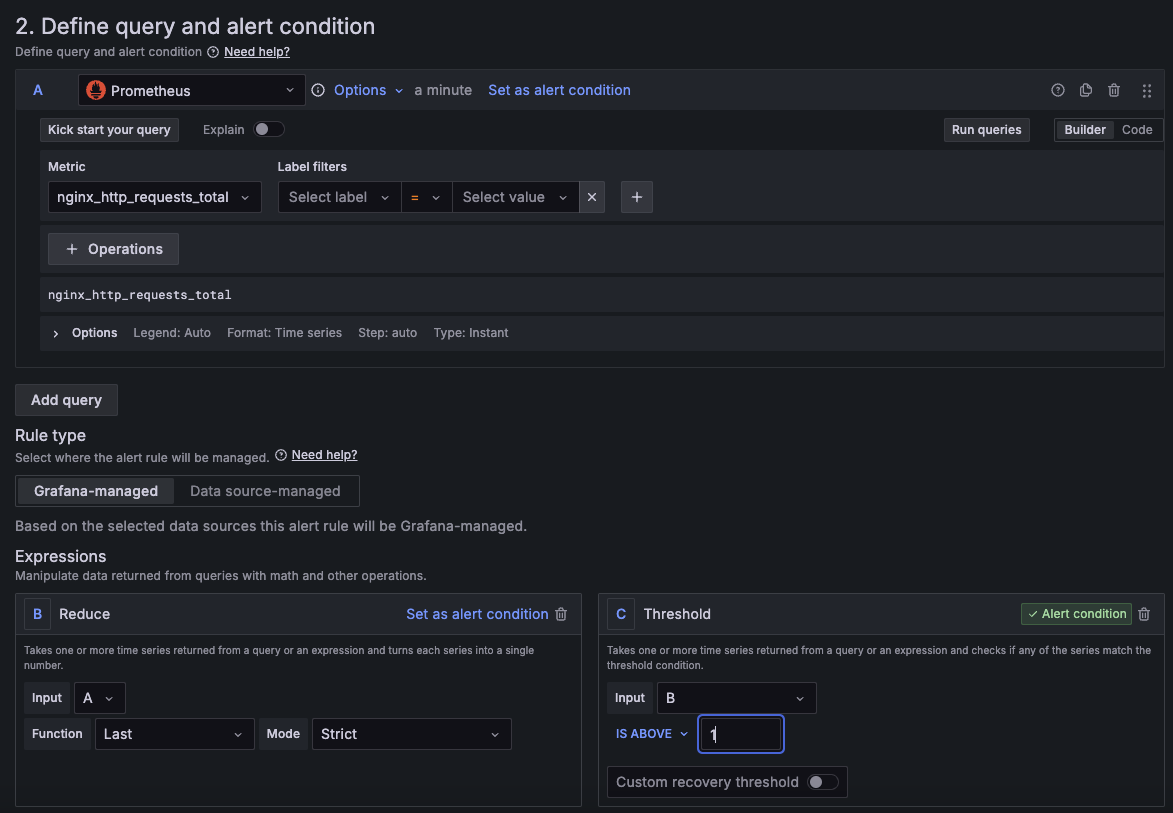
1분 간격으로 nginx 에 들어온 request 전체 요청 수가 1 이상이면 알람을 보내도록 설정을 해줍니다.
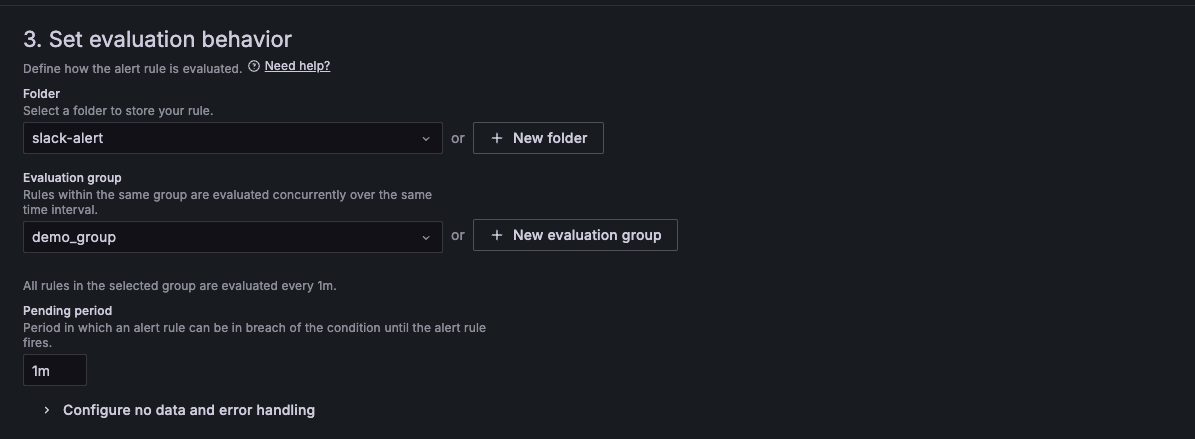
slack-alert라는 이름의 폴더를 생성해줍니다. Evaluation Interval은 1m 로 설정하여 생성해줍니다.
Pending period도 1m 로 설정합니다 .
1분마다 규칙을 검사하고, 1분 기다렸다가 알람을 보낼 것입니다. .
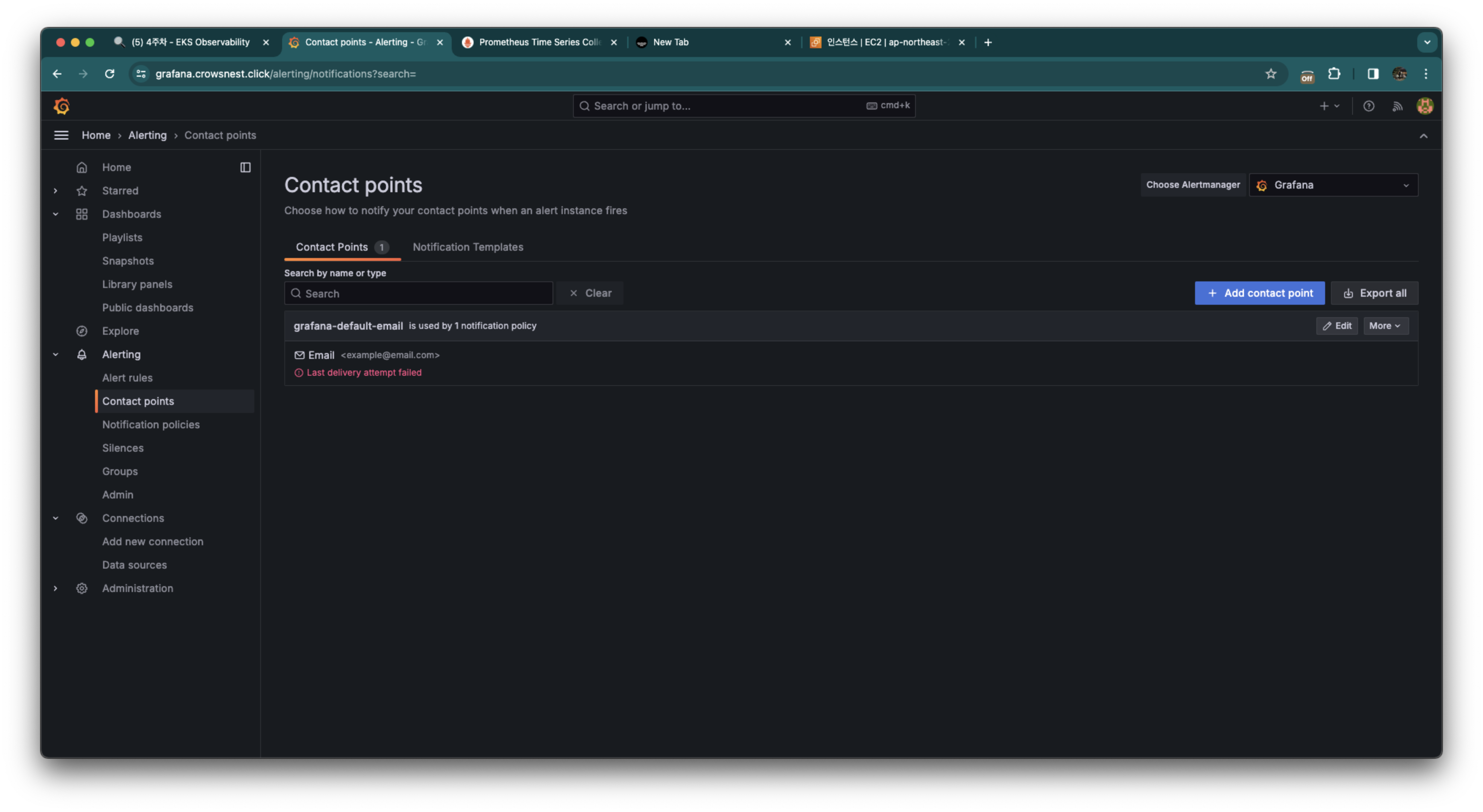
contact points를 들어온 뒤 오른쪽 위에 Add contact point를 클릭해줍니다.
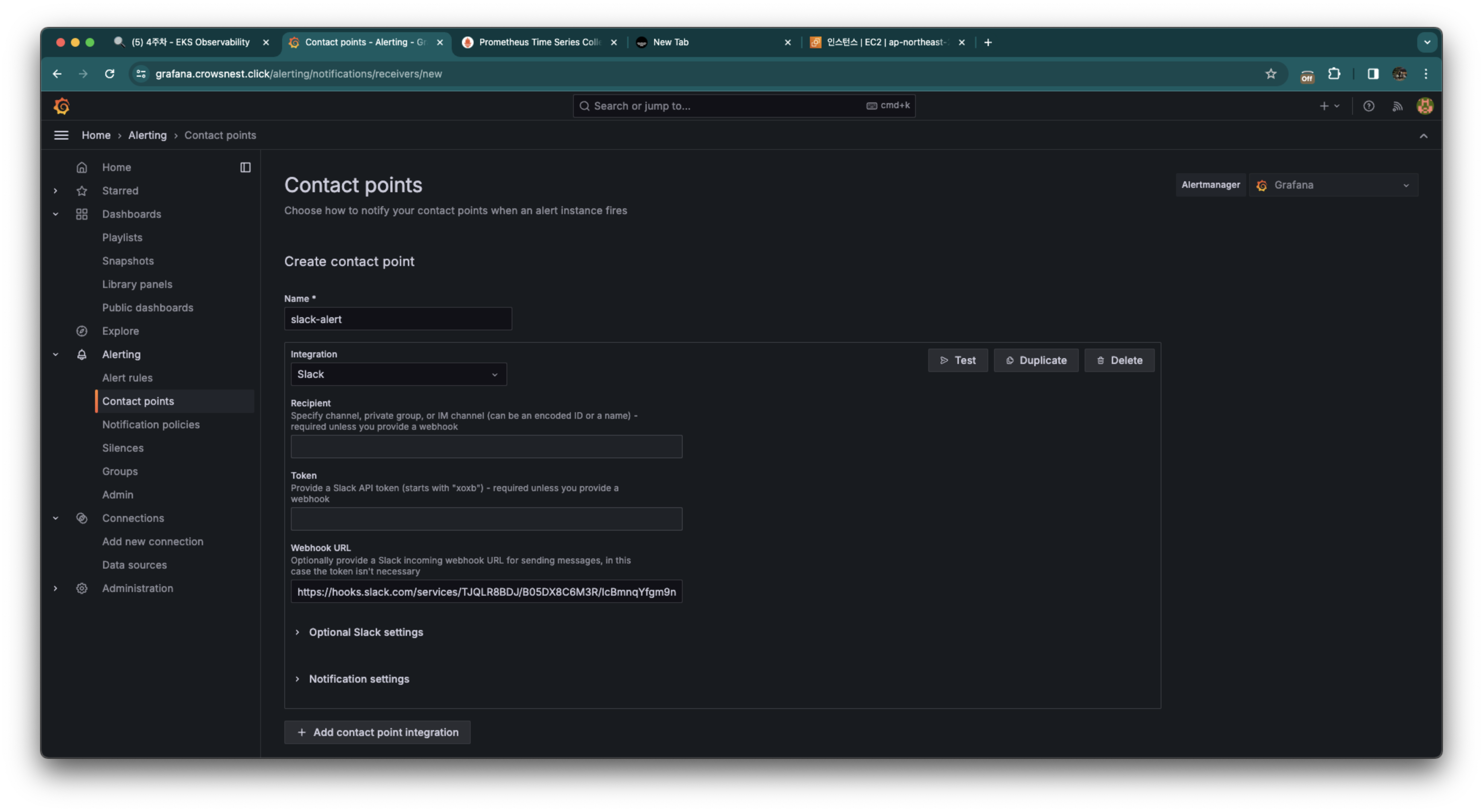
Integration에 slack을 넣어주고, 슬랙 webhook url을 넣어줍니다.
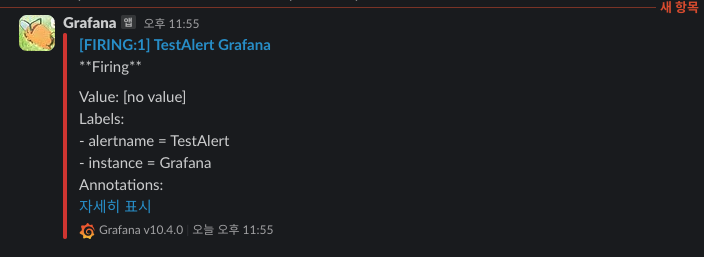
Test를 누르면 해당 채널에 알림이 온 것을 확인할 수 있습니다.
정상이니 Save Contact point를 눌러서 저장을 해줍니다.
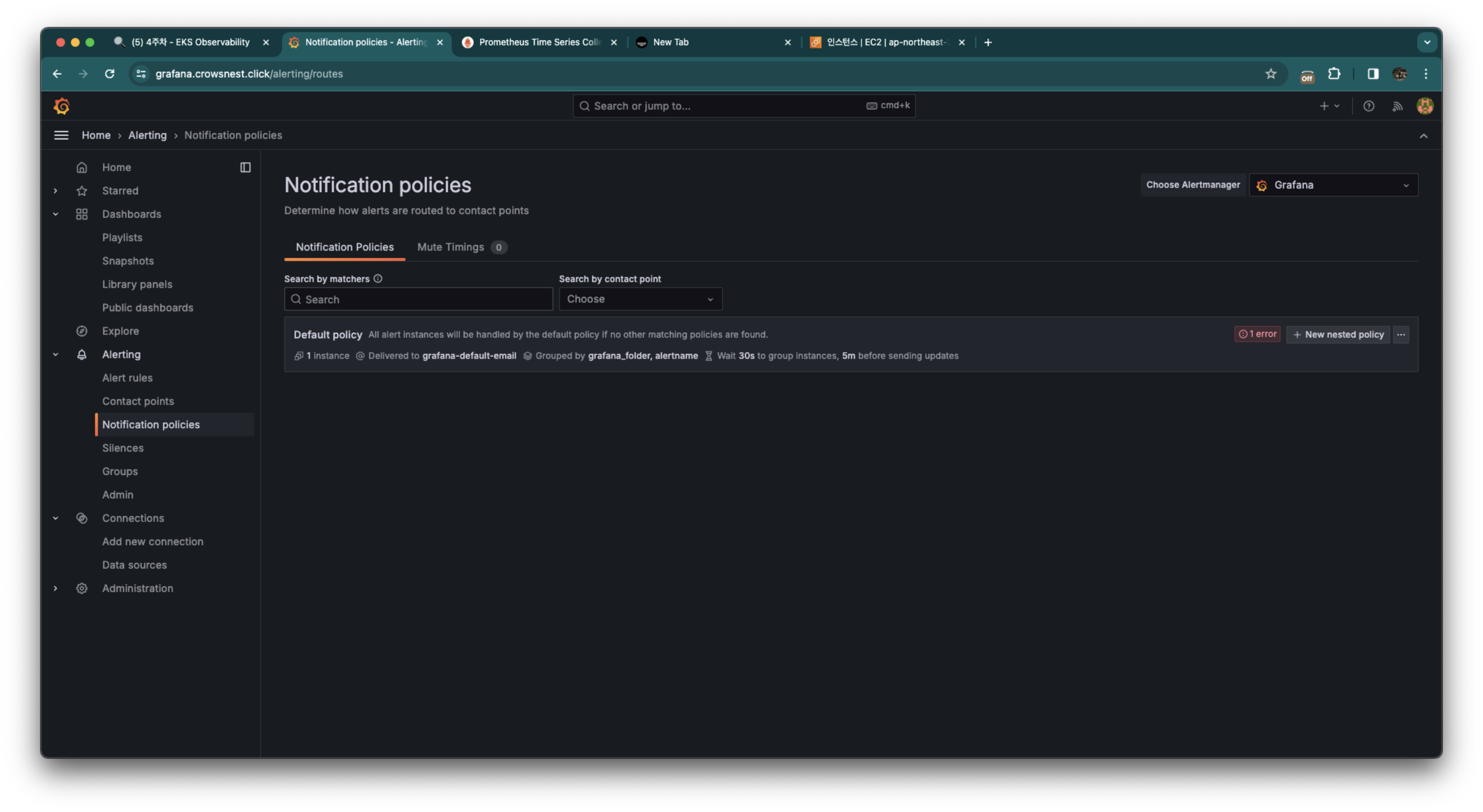
Notification policies를 클릭하고 default poicy를 편집해줍니다.
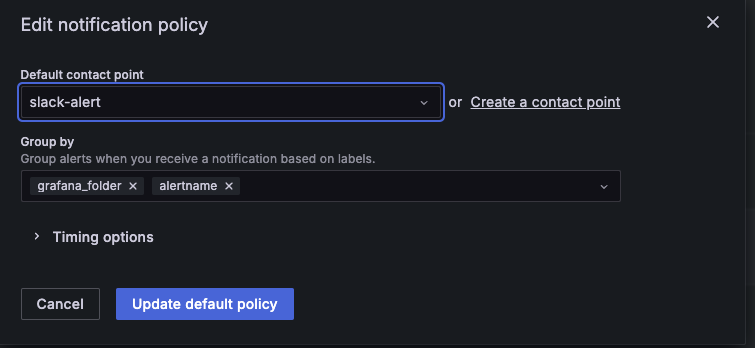
아까 만든 컨택 포인트로 수정해준 뒤 오른쪽 밑 update default policy를 누릅니다.
while true; do curl -s <https://nginx.$MyDomain> -I | head -n 1; date; done
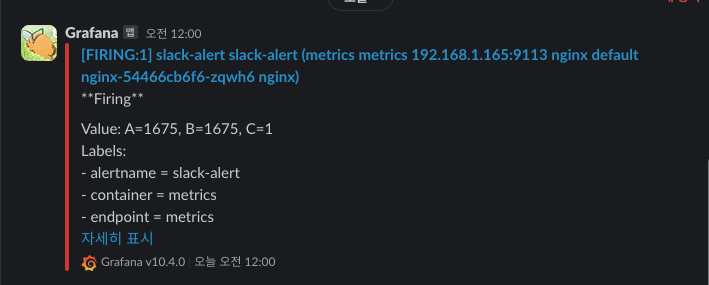
위 명령으로 엄청 요청을 보내면 알람이 Slack에 전송되는것을 확인할 수 있습니다.
후기
평소 지식적으로 특히 부족하다고 생각했던 부분이 모니터링과 관측가능성 구성이었는데,
덕분에 쿠버네티스를 사용해서 어떻게 구성할 수 있을지 느낌 얻을 수 있었습니다.
모니터링은 제가 설정하는것보다 자동으로 잡아주는것들이 많아서 편하네요!
벌써 반을 했군요, 나머지 반도 힘내서 공부해보겠습니다!





댓글