about me

20'S LIFE IN SYDNEY and BUSAN
가용성과 확장성 Review
가용성
가용성(Availability)이란 시스템이 정상적으로 사용 가능한 정도
정상적인 사용시간(Uptime)을 정상사용시간과 사용불가 시간을 합친 전체사용시간(Uptime + Downtime)으로 나눈값을 표현하며, 예를 들어 가용성 99.95%는 1년에 약 4시간 22분의 다운타임이 됩니다.
위의 수식에 따라서 서비스 사용 불가능 시간을 최소로 만들어야 가용성이 올라갑니다.
가용성의 핵심은 바로 단일 장애점(Single Point of Failure)을 없애는 것이어야 합니다.
즉, 어떤 한 노드가 장애가 발생해도, 동일한 처리 능력을 가진 다른 노드로 대체될 수 있어야 합니다. 이를 위해 필요한 것이 바로 시스템 확장입니다.
확장성
확장 가능한 시스템: 요구되는 시스템의 성능에 따라 동적으로 서버 구성이 변경되고, 시스템 처리 능력을 최적화할 수 있는 시스템을 의미합니다.
- 시스템의 처리 능력을 확장하는 방법:
하나의 머신에서 메모리나 CPU를 늘리는 수직 확장(Scale Up), 머신의 인스턴스 수를 늘리는 수평 확장(Scale Out)
- 수직 확장은 한계가 있으므로, 수평 확장이 가능할 때 확장성이 좋다고 평가할 수 있습니다.
- AWS와 같은 클라우드 사업자가 확장성을 보증하는 경우도 존재합니다. 기본적으로 AWS 등에서 제공하는 서버리스 서비스들은 확장성이 좋습니다.
수직 확장을 고려할 경우 다운타임이 발생하여 가용성이 떨어지며, 성능 제한이 있으므로 반드시 한계를 이해해야 합니다.
클라우드 환경에서 부하 테스트를 하는 목적
시스템 확장성을 가졌는지 확인
성능을 개선하기 위해 확장해야 하는 시스템이 무엇인지 파악
부하가 많이 발생할 때 문제 상황 개선
각 시스템의 병목 지점을 예측하고 진단 및 개선
어떤 부분을 확장할 것인가?: 확장성에 대한 특징 파악
어떤 부분을 확장해야 성능이 높아질지를 고민하기에 앞서, Throughput과 관련한 지표를 먼저 이해할 필요가 있습니다. Throughput은 시간 당 처리량으로, 시스템의 성능 지표는 RPS(request per second), TPS(transaction per second)와 같은 단위로 표현됩니다.
Throughput은 데이터 전송량에 포커스를 맞춘 성능 지표입니다.
한편 볼륨의 성능을 측정할 경우에는 IOPS(Input/Output per second)라는 단위를 사용합니다.
성능을 측정할 때는, 인프라 내의 구성요소(티어)로 구분된 각 요소를 구분하지 않고 통합해서, 특정 작업이 얼마만큼의 Throughput을 갖는지를 측정합니다.
부하가 많이 발생할 때의 문제 상황 개선
사용자 요청이 많아지는 경우, 즉 부하가 많이 발생하면 실제로 시스템은 어떤 문제를 일으킬까요?
응답 속도(Latency) 저하
시스템 잠금(Lock) 경합
부하 발생시 애플리케이션 또는 서버 에러 발생
데이터 일관성 문제와 손실
이러한 문제 상황을 해결할 수 있을 만큼의 부하의 수용 범위를 파악해야 합니다.
Throughput과 Latency
시스템 성능 지표의 주요 메트릭은 단연 Throughput과 Latency 입니다. 부하 테스트에서는 이 두가지 지표를 사용하여 평가합니다.
Throughput
시간 당 처리량을 의미합니다. 웹 애플리케이션 성능 지표로서의 throughput의 대표적인 예는 다음과 같습니다.
1초에 처리하는 HTTP 요청 수 (rps)
(동영상 스트리밍 서비스와 같이 대역폭이 중요한 경우) 네트워크로 전송되는 데이터 전송 속도
Latency
처리 시간을 의미합니다.
사용자가 어떤 웹페이지를 보기 위한 Latency는 사용자의 인터넷 환경, 브라우저 등의 개별 환경에 대한 변수가 존재
즉, "네트워크를 통한 데이터 왕복 시간"도 포함합니다.
그러나 성능 테스트를 진행할 때에는, 사용자 환경에 따른 변인을 통제하거나, 애초에 네트워크 상황을 고려하지 않고 테스트를 진행
이후 언급하는 Latency는 네트워크 상황을 고려하지 않은 시스템이 요청을 받고 응답을 줄 때까지의 시간만을 의미할 것입니다.
하위 시스템으로 구성된 경우에서의 Throughput과 Latency
다음 고속도로의 비유를 통해 Throughput과 Latency를 이해할 수 있습니다.
여기서 하위 시스템은 서울/대구/부산 각각의 도시를 의미하며, 각 도시 간에는 서로 다른 Throughput과 Latency를 가진 고속도로 두 개가 존재한다고 가정합시다.
이 때 Latency는 대기 시간을 포함한, 각 하위 시스템 처리 시간의 총 합으로 계산합니다.
반면 Throughput은 하위 시스템 Throughput 중 최솟값을 전체 시스템의 Throughput으로 계산합니다.
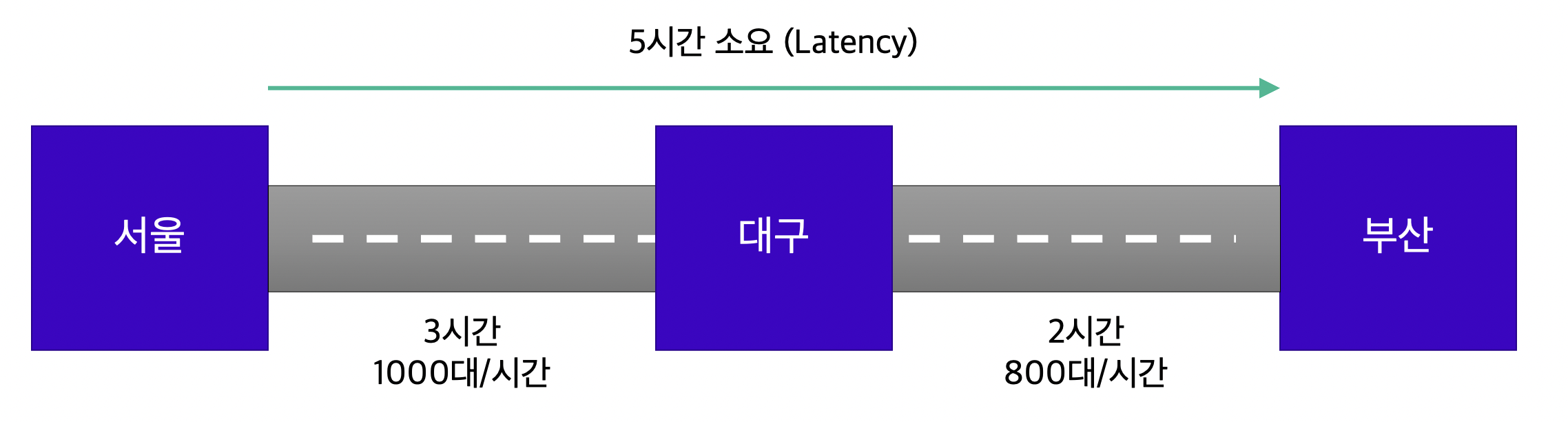
서울-부산 간 Throughput: 각 구간에 도달하는 차량 대수 중 최소값인 800대/시간
서울-부산 간 Latency: 각 구간의 소요 시간 합계인 5시간




댓글