about me

20'S LIFE IN SYDNEY and BUSAN
직면한 문제들
필자는 AWS의 오토스케일링을 베이스로 한 API 서버를 구성하여, DB를 연결하였고, 프로젝트 요구 사항이었던 엘라스틱 캐시를 DB와 더불어서 어떻게 써야할 지 고민하고있었다.
내가 이해한바와 시도해본 방법
처음에 시도했던 방법은 원본 데이터 베이스를 두고, 레플리카를 두는 것이었다. 그리고 원본데이터베이스에는 쓰기전용으로 쓰고, 레플리카 데이터 베이스를 읽기전용으로 쓰는 것이었다.
1. 그리고 API서버에서 GET요청을 할 때
2. 캐시 데이터베이스에 GET요청을 한다.
있다면 서버에 반환해주면 되고, 없다면 원본 DB의 내용을 똑같이 가지고 있는 레플리카 DB를 읽기전용으로 만들었으니, 거기서 가져온다.
이런 과정이었다. 캐시가 처음에 내용을 알아서 가져오는줄 알았다.
그런데
https://stackoverflow.com/questions/62750685/connecting-elasticache-with-rds
스택 오버플로우를 참고하니 ElastiCache에서 자동으로 DB에서 연결되어서 가져오는건 없다고 한다…
그럼 내가 생각한 아키텍쳐의 모양이 안맞게 되는거다…
그리고 엘라스틱 캐시의 역할을 검색하던 중 Write Through 의 방식으로 쓰는것을 보았다.
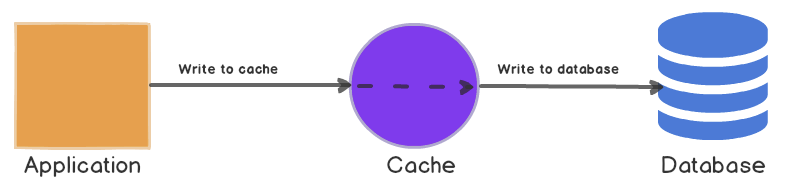
간단하게 말하자면 데이터가 캐시에 기록됨과 동시에 디비에 같이 기록되게 해주는 것이다. 그리고 캐시와 메인 데이터베이스는 데이터의 일관성을 유지할수 있게 된다고 한다.
그런데 mysql 을 비교기준으로 삼았을 때 redis가 읽기로 쓸 때, 약 10배정도 빠르니까 결국 데이터를 받아올 때(GET)는 캐시에서만 받아오게된다.
엘라스틱 캐시도 결국 데이터 값을 저장하는 데이터베이스의 종류이고, 이렇게되면 원본 데이터베이스의 역할은 캐시와 같은 데이터를 가진 백업 데이터베이스의 역할로 써질 뿐이었다.
하지만 이 방식에서도 건질 건 있었는데, 캐시 데이터베이스에 내가 값을 넣을 수 있고, 그렇게 해야된다는것이다. 이와 더불어 세션을 이용하면 유효기간도 설정할수있더라.
그리고 우리가 받았던 프로젝트의 요구사항을 다시 읽어보았다.
데이터 내구성을 보장하기 위해 RDS는 복제본이 만들어져야 하며, 빠른 예약 정보 검색을 위해 쿼리결과는 ElastiCache를 통해 캐싱이 되어야 합니다.
위에 내가 했던 실수들과 함께 요구사항을 읽어보니 내가 만들어야할 아키텍쳐와 연결성이 눈에 조금 그려졌다.
그리고 꼭 해야하는 핵심을 두가지 그려봤다.
1. 캐시는 내가 값을 넣지 않으면 비어있는 데이터베이스라는 것
2. RDS(원본 데이터베이스)의 복제본은 데이터의 내구성만 보장하는것
그리고 위 두 사항을 생각하고 그린 아키텍쳐는

1. API서버에서 GET 요청이 오면 캐시 데이터베이스에서 데이터를 찾는다.
2. 찾는 데이터가 있으면 그대로 반환해주고, 없으면 원본 RDS에 가서 데이터를 찾는다.
3. 원본 RDS에서 반환해주는 데이터를 가져옴과 동시에 그 다음에도 쓰게 될 데이터라고 판단하여 캐시에 똑같이 넣어준다.
이 로직으로 위에 있었던 고민인
Write Through 방식일 때 내구성을 위해서만 쓰던 원본db의 애매한 역할까지 해결이 되었다.




댓글